Optimización mediante procesamiento por lotes¶
Introducción¶
Las plataformas de juego deben enviar un conjunto de instrucciones a la GPU para decirle qué y dónde dibujar. Estas instrucciones se envían utilizando instrucciones comunes llamadas API (Interfaces de Programación de Aplicaciones). Ejemplos de API gráficas son OpenGL, OpenGL ES y Vulkan.
Las diferentes API tienen diferentes costos al dibujar objetos. OpenGL se encarga de mucho trabajo por parte del usuario en el controlador de la GPU, a costa de llamadas de dibujo más costosas. Como resultado, las aplicaciones a menudo pueden acelerarse al reducir el número de llamadas de dibujo (draw calls).
Dibujar llamadas¶
En 2D, necesitamos decirle a la GPU que renderice una serie de primitivas (rectángulos, líneas, polígonos, etc.). La técnica más obvia es decirle a la GPU que renderice una primitiva a la vez, proporcionándole información como la textura utilizada, el material, la posición, el tamaño, etc., y luego decir "¡Dibuja!" (esto se llama llamada de dibujo o draw call).
Si bien esto es conceptualmente simple desde el punto de vista del motor, las GPUs funcionan muy lentamente cuando se usan de esta manera. Las GPUs funcionan de manera mucho más eficiente si les indicas que dibujen un conjunto de primitivas similares en una sola llamada de dibujo, lo que llamaremos un "batch" (lote).
Resulta que no solo funcionan un poco más rápido cuando se usan de esta manera, sino que funcionan mucho más rápido.
Dado que Godot está diseñado para ser un motor de propósito general, las primitivas que ingresan al renderizador de Godot pueden estar en cualquier orden, a veces similares y a veces diferentes. Para combinar la naturaleza de propósito general de Godot con las preferencias de batching de las GPUs, Godot cuenta con una capa intermedia que puede agrupar automáticamente primitivas siempre que sea posible y enviar estos lotes a la GPU. Esto puede aumentar el rendimiento de renderizado sin requerir muchos (o ningún) cambio en tu proyecto de Godot.
Cómo funciona¶
Las instrucciones llegan al renderizador desde tu juego en forma de una serie de elementos, cada uno de los cuales puede contener uno o más comandos. Los elementos corresponden a nodos en el árbol de escenas, y los comandos corresponden a primitivas como rectángulos o polígonos. Algunos elementos, como TileMaps y texto, pueden contener una gran cantidad de comandos (tiles y glifos, respectivamente). Otros, como los sprites, pueden contener solo un comando (un rectángulo).
El batcher utiliza dos técnicas principales para agrupar las primitivas:
Los elementos consecutivos se pueden unir entre sí.
Los comandos consecutivos dentro de un elemento se pueden unir para formar un batch.
Rompiendo el batching¶
El batching solo puede ocurrir si los elementos o comandos son lo suficientemente similares como para ser renderizados en una sola llamada de dibujo. Ciertos cambios (o técnicas), por necesidad, impiden la formación de un batch continuo, esto se conoce como "romper el batching".
El batching se romperá debido a (entre otras cosas):
Cambio de textura.
Cambio de material.
Cambio en el tipo de primitiva (por ejemplo, pasar de rectángulos a líneas).
Nota
Por ejemplo, si dibujas una serie de sprites, cada uno con una textura diferente, no es posible agruparlos en un batch.
Determinando el orden de renderizado¶
La pregunta surge, si solo se pueden dibujar juntos elementos similares en un batch, ¿por qué no revisamos todos los elementos en una escena, agrupamos todos los elementos similares y los dibujamos juntos?
En 3D, a menudo esto es exactamente cómo funcionan los motores. Sin embargo, en el renderizador 2D de Godot, los elementos se dibujan en el "orden del pintor", de atrás hacia adelante. Esto garantiza que los elementos en la parte delantera se dibujen encima de los elementos anteriores cuando se superponen.
Esto también significa que si intentamos dibujar objetos en función de la textura, el orden del pintor puede romperse y los objetos se dibujarán en el orden incorrecto.
En Godot, este orden de atrás hacia delante es determinado por:
El orden de los objetos en el árbol de la escena.
El Z index de objetos.
La canvas layer.
Nodos YSort.
Nota
Puedes agrupar objetos similares para facilitar el procesamiento por lotes. Si bien esto no es un requisito de tu parte, puedes considerarlo como un enfoque opcional que puede mejorar el rendimiento en algunos casos. Consulta la sección Disagosticos para ayudarte a tomar esta decisión.
Un truco¶
Y ahora, un juego de manos. Aunque la idea del orden del pintor es que los objetos se representen de atrás hacia adelante, considera 3 objetos A, B y C que contienen 2 texturas diferentes: césped y madera.

En el orden del pintor, se ordenan de la siguiente manera:
A - wood
B - grass
C - wood
Debido a los cambios de textura, no se pueden agrupar y se representarán en 3 llamadas de dibujo por separado.
Sin embargo, el orden del pintor solo es necesario bajo la suposición de que se dibujarán encima uno del otro. Si relajamos esa suposición, es decir, si ninguno de estos 3 objetos se superpone, no hay necesidad de mantener el orden del pintor. El resultado renderizado será el mismo. ¿Qué tal si aprovechamos esto?
reordenamiento de Items¶

Resulta que podemos reordenar los objetos. Sin embargo, solo podemos hacerlo si los objetos cumplen las condiciones de una prueba de superposición para asegurarnos de que el resultado final será el mismo que si no se hubieran reordenado. La prueba de superposición es muy eficiente en términos de rendimiento, pero no es completamente gratuita, por lo que hay un ligero costo al mirar hacia adelante para decidir si los objetos pueden reordenarse. El número de objetos para mirar hacia adelante y reordenar se puede establecer en la configuración del proyecto (ver más abajo) para equilibrar los costos y beneficios en tu proyecto.
A - wood
C - wood
B - grass
Dado que la textura solo cambia una vez, podemos representar lo anterior en solo 2 llamadas de dibujo.
Luces¶
Aunque el trabajo del sistema de agrupamiento por lo general es bastante sencillo, se vuelve considerablemente más complejo cuando se utilizan luces 2D. Esto se debe a que las luces se dibujan utilizando pases adicionales, uno por cada luz que afecta a la primitiva. Considera 2 sprites A y B, con textura y material idénticos. Sin luces, se agruparían juntos y se dibujarían en una sola llamada de dibujo. Pero con 3 luces, se dibujarían de la siguiente manera, cada línea siendo una llamada de dibujo:

A
A - light 1
A - light 2
A - light 3
B
B - light 1
B - light 2
B - light 3
Eso es muchas llamadas de dibujo: 8 para solo 2 sprites. Ahora, considera que estamos dibujando 1,000 sprites. El número de llamadas de dibujo se vuelve rápidamente astronómico y el rendimiento se ve afectado. Esto es en parte por qué las luces tienen el potencial de disminuir drásticamente la velocidad de renderizado en 2D.
Sin embargo, si recuerdas el truco del mago que mencionamos anteriormente sobre el reordenamiento de elementos, resulta que podemos usar el mismo truco para ¡evitar el orden del pintor con las luces!
Si A y B no se superponen, podemos representarlos juntos en un lote, por lo que el proceso de dibujo es el siguiente:

AB
AB - light 1
AB - light 2
AB - light 3
Eso son solo 4 llamadas de dibujo. No está mal, ya que eso representa una reducción de 2×. Sin embargo, considera que en un juego real, es posible que estés dibujando cerca de 1,000 sprites.
Antes: 1000 × 4 = 4,000 llamadas de dibujo.
Después: 1 × 4 = 4 llamadas de dibujo.
Eso representa una disminución de 1000× en las llamadas de dibujo y debería brindar un aumento significativo en el rendimiento.
Prueba de superposición¶
Sin embargo, al igual que con el reordenamiento de elementos, las cosas no son tan simples. Primero debemos realizar la prueba de superposición para determinar si podemos unir estas primitivas. Esta prueba de superposición tiene un pequeño costo. Una vez más, puedes elegir el número de primitivas a analizar en la prueba de superposición para equilibrar los beneficios frente al costo. Con las luces, generalmente los beneficios superan con creces los costos.
También debemos tener en cuenta que dependiendo de la disposición de las primitivas en la vista, la prueba de superposición a veces fallará (debido a que las primitivas se superponen y, por lo tanto, no deben unirse). En la práctica, la disminución en las llamadas de dibujo puede ser menos drástica que en una situación perfecta sin superposiciones en absoluto. Sin embargo, el rendimiento generalmente es mucho mayor que sin esta optimización de iluminación.
Tijera ligera¶
El agrupamiento puede dificultar la exclusión de objetos que no se ven afectados o se ven parcialmente afectados por una luz. Esto puede aumentar considerablemente los requisitos de velocidad de relleno y ralentizar el renderizado. La velocidad de relleno es la velocidad a la que se colorean los píxeles. Es otro posible cuello de botella que no está relacionado con las llamadas de dibujo.
Para contrarrestar este problema (y acelerar la iluminación en general), el agrupamiento introduce el recorte de luces (light scissoring). Esto permite el uso del comando OpenGL glScissor(), que identifica un área fuera de la cual la GPU no renderizará píxeles. Podemos optimizar en gran medida la velocidad de relleno al identificar el área de intersección entre una luz y una primitiva, y limitar el renderizado de la luz solo a esa área.
El recorte de luces se controla con la configuración del proyecto scissor_area_threshold. Este valor está comprendido entre 1.0 y 0.0, siendo 1.0 sin recorte (sin recorte de luces) y 0.0 recorte de luces en todas las circunstancias. La razón de esta configuración es que puede haber algún costo pequeño al realizar el recorte en ciertos dispositivos. Dicho esto, el recorte de luces generalmente debería mejorar el rendimiento cuando se utiliza iluminación 2D.
La relación entre el umbral y si se realiza una operación de recorte no siempre es directa. En general, representa el área de píxeles que potencialmente se "ahorra" mediante una operación de recorte (es decir, la tasa de llenado ahorrada). Con 1.0, se necesitaría guardar todos los píxeles de la pantalla, lo cual rara vez sucede (si es que alguna vez sucede), por lo que se desactiva. En la práctica, los valores útiles están cerca de 0.0, ya que solo un pequeño porcentaje de píxeles necesita ser guardado para que la operación sea útil.
Es probable que los usuarios no necesiten preocuparse por la relación exacta, pero se incluye en el apéndice por interés: Cálculo del umbral de recorte de luz
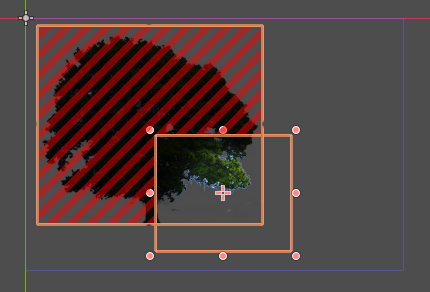
En la esquina inferior derecha se encuentra una luz, el área en rojo representa los píxeles guardados por la operación de recorte. Solo es necesario renderizar la intersección.¶
Horneado de vértice¶
El sombreador de la GPU recibe instrucciones sobre qué dibujar de 2 formas principales:
Uniforms de shader (por ejemplo, color de modulación, transformación de objetos).
Atributos de vértices (color de vértice, transformación local).
Sin embargo, dentro de una sola llamada de dibujo (lote), no podemos cambiar los uniforms. Esto significa que, de manera ingenua, no podríamos agrupar elementos o comandos que cambien final_modulate o la transformación de un elemento. Desafortunadamente, eso ocurre en muchos casos. Por ejemplo, los sprites suelen ser nodos individuales con su propia transformación de elementos y también pueden tener su propia modulación de color.
Para solucionar este problema, la agrupación (batching) puede "hornear" algunas de las uniforms en los atributos de vértice.
La transformación del objeto se puede combinar con la transformación local y enviarse en un atributo de vértice.
El color final modulado se puede combinar con los colores de vértice y enviarse en un atributo de vértice.
En la mayoría de los casos, esto funciona bien, pero esta simplificación se rompe si un shader espera que estos valores estén disponibles de forma individual en lugar de combinados. Esto puede ocurrir en shaders personalizados.
Sombreadores personalizados¶
Como resultado de la limitación descrita anteriormente, ciertas operaciones en shaders personalizados impedirán la generación de vértices y, por lo tanto, disminuirán el potencial de agrupamiento. Si bien estamos trabajando para reducir estos casos, actualmente se aplican las siguientes advertencias:
La lectura o escritura de
COLORoMODULATEdeshabilita la generación de colores de vértice.La lectura de
VERTEXdeshabilita la generación de posiciones de vértice.
Configuración del proyecto¶
Para optimizar el agrupamiento, hay disponibles una serie de ajustes de proyecto. Por lo general, puedes dejarlos en los valores predeterminados durante el desarrollo, pero es una buena idea experimentar para asegurarte de obtener el máximo rendimiento. Dedicar un poco de tiempo a ajustar los parámetros a menudo puede generar mejoras significativas en el rendimiento con muy poco esfuerzo. Consulta las descripciones emergentes (tooltips) en la configuración del proyecto para obtener más información al respecto.
renderizado / procesamiento por lotes / opciones¶
use_batching - Activa o desactiva el agrupamiento.
use_batching_in_editor - Activa o desactiva el agrupamiento en el editor de Godot. Esta configuración no afecta de ninguna manera al proyecto en ejecución.
single_rect_fallback - Esta es una forma más rápida de dibujar rectángulos que no se pueden agrupar. Sin embargo, puede generar parpadeo en algunos dispositivos, por lo que no se recomienda su uso.
renderizado / procesamiento por lotes / parámetros¶
max_join_item_commands - Una de las formas más importantes de lograr el agrupamiento es unir elementos (nodos) adyacentes adecuados, pero solo se pueden unir si los comandos que contienen son compatibles. El sistema debe realizar una búsqueda anticipada a través de los comandos en un elemento para determinar si se puede unir. Esto tiene un pequeño costo por comando y no vale la pena unir elementos con un gran número de comandos, por lo que el mejor valor puede depender del proyecto.
colored_vertex_format_threshold - Al generar los colores en los vértices se obtiene un formato de vértice más grande. No siempre vale la pena hacerlo a menos que haya muchos cambios de color en un elemento unido. Este parámetro representa la proporción de comandos que contienen cambios de color / el total de comandos, por encima del cual se cambia a colores generados en los vértices.
batch_buffer_size - Esto determina el tamaño máximo de un lote (batch). No tiene un gran efecto en el rendimiento, pero puede valer la pena reducirlo en dispositivos móviles si la memoria RAM es limitada.
item_reordering_lookahead - El reordenamiento de elementos puede ayudar especialmente con sprites entrelazados que utilizan diferentes texturas. La búsqueda anticipada para la prueba de superposición tiene un costo pequeño, por lo que el mejor valor puede variar según el proyecto.
renderizado/batching/luces¶
scissor_area_threshold - Vea recorte de luces.
max_join_items - Unir elementos antes de aplicar la iluminación puede aumentar significativamente el rendimiento. Esto requiere una prueba de superposición, que tiene un costo pequeño, por lo que los costos y beneficios pueden depender del proyecto, y, por lo tanto, el mejor valor a utilizar puede variar.
renderizado/batching/depuración¶
flash_batching - Esta es una función exclusivamente para depuración que permite identificar regresiones entre el agrupamiento y el renderizador heredado. Cuando está activada, se alternan el agrupamiento y el renderizador heredado en cada fotograma. Esto disminuirá el rendimiento y no debe utilizarse en la exportación final, solo para pruebas.
diagnose_frame - Esto imprimirá periódicamente un registro de diagnóstico de agrupamiento en la IDE de Godot o en la consola.
renderizado/batcing/precisión¶
uv_contract - En algunos dispositivos (especialmente en algunos dispositivos Android), ha habido informes de que los tiles del tilemap se dibujan ligeramente fuera de su rango UV, lo que genera artefactos en los bordes como líneas alrededor de los tiles. Si observas este problema, intenta habilitar "uv_contract". Esto realiza una pequeña contracción en las coordenadas UV para compensar los errores de precisión en los dispositivos.
uv_contract_amount - Esperemos que el valor predeterminado resuelva los artefactos en la mayoría de los dispositivos, pero este valor se puede ajustar en caso necesario.
Disagosticos¶
Aunque puedes cambiar los parámetros y examinar el efecto en la velocidad de fotogramas, esto puede sentirse como trabajar a ciegas, sin tener idea de lo que está sucediendo internamente. Para ayudar con esto, el agrupamiento ofrece un modo de diagnóstico que imprimirá periódicamente (en la IDE o en la consola) una lista de los lotes que se están procesando. Esto puede ayudar a identificar situaciones en las que el agrupamiento no ocurre como se pretendía y te ayudará a solucionar estas situaciones para obtener el mejor rendimiento posible.
Leyendo un diagnóstico¶
canvas_begin FRAME 2604
items
joined_item 1 refs
batch D 0-0
batch D 0-2 n n
batch R 0-1 [0 - 0] {255 255 255 255 }
joined_item 1 refs
batch D 0-0
batch R 0-1 [0 - 146] {255 255 255 255 }
batch D 0-0
batch R 0-1 [0 - 146] {255 255 255 255 }
joined_item 1 refs
batch D 0-0
batch R 0-2560 [0 - 144] {158 193 0 104 } MULTI
batch D 0-0
batch R 0-2560 [0 - 144] {158 193 0 104 } MULTI
batch D 0-0
batch R 0-2560 [0 - 144] {158 193 0 104 } MULTI
canvas_end
Este es un diagnóstico típico.
joined_item: Un joined_item puede contener 1 o más referencias a elementos (nodos). En general, es preferible tener joined_items que contengan muchas referencias en lugar de tener muchos joined_items que contengan una sola referencia. Si los elementos se pueden unir se determinará por su contenido y su compatibilidad con el elemento anterior.
batch R: Un lote (batch) que contiene rectángulos. El segundo número es la cantidad de rectángulos. El segundo número entre corchetes cuadrados es el ID de textura de Godot y los números entre llaves representan el color. Si el lote contiene más de un rectángulo, se agrega
MULTIa la línea para facilitar su identificación. VerMULTIes positivo, ya que indica que el agrupamiento se realizó correctamente.batch D: Un lote (batch) predeterminado que contiene todo lo demás que no se agrupa actualmente.
Lotes predeterminados¶
El segundo número que sigue a los lotes predeterminados es la cantidad de comandos en el lote, y le sigue un breve resumen del contenido:
l - line
PL - polyline
r - rect
n - ninepatch
PR - primitive
p - polygon
m - mesh
MM - multimesh
PA - particles
c - circle
t - transform
CI - clip_ignore
Es posible que veas lotes predeterminados "dummy" que no contienen comandos; puedes ignorar esos lotes.
Preguntas Frecuentes¶
No experimento un gran aumento de rendimiento al habilitar el agrupamiento.¶
Prueba la función de diagnóstico para ver cuánto agrupamiento se está produciendo y si se puede mejorar
Prueba cambiar los parámetros de agrupamiento en la Configuración del Proyecto.
Considera que el agrupamiento puede no ser tu cuello de botella (ver cuellos de botella).
Experimento una disminución en el rendimiento al utilizar el agrupamiento.¶
Prueba los pasos descritos anteriormente para aumentar la cantidad de oportunidades de agrupamiento.
Intenta habilitar single_rect_fallback.
El método de fallback de un solo rectángulo es el valor predeterminado utilizado sin agrupamiento, y es aproximadamente el doble de rápido. Sin embargo, puede generar parpadeo en algunos dispositivos, por lo que se desaconseja su uso.
Después de probar las opciones mencionadas anteriormente, si tu escena aún presenta un rendimiento deficiente, considera desactivar el agrupamiento.
Utilizo shaders personalizados y los objetos no se agrupan en lotes.¶
Los shaders personalizados pueden ser problemáticos para el agrupamiento en lotes. Consulta la sección de shaders personalizados
Estoy viendo artefactos de líneas que aparecen en cierto hardware.¶
Consulta la configuración del proyecto uv_contract, la cual se puede utilizar para resolver este problema.
Utilizo un gran número de texturas, por lo que pocos objetos se están agrupando en lotes.¶
Considera utilizar atlases de texturas. Además de permitir el agrupamiento en lotes, estos reducen la necesidad de cambios de estado asociados con el cambio de texturas.
Apendice¶
Primitivas agrupadas en lotes¶
No todas las primitivas pueden agruparse en lotes. Tampoco se garantiza el agrupamiento en lotes, especialmente con primitivas que utilizan un borde suavizado. Los siguientes tipos de primitivas están actualmente disponibles:
RECT
NINEPATCH (dependiendo del modo de envoltura)
POLY
LINE
Con primitivas no agrupadas en lotes, es posible obtener un mejor rendimiento al dibujarlas manualmente utilizando polígonos en una función _draw(). Consulta Dibujos personalizados en 2D para obtener más información.
Cálculo del umbral de recorte de luz¶
La proporción real del área de píxeles de la pantalla utilizada como umbral es el valor de scissor_area_threshold elevado a la potencia de 4.
Por ejemplo, en una pantalla de tamaño 1920×1080, hay 2,073,600 píxeles.
Con un umbral de 1,000 píxeles, la proporción sería:
1000 / 2073600 = 0.00048225
0.00048225 ^ (1/4) = 0.14819
Entonces, un valor de *scissor_area_threshold de 0.15 sería un valor razonable para probar.
Tomando el camino alternativo, para la instancia con un valor de scissor_area_threshold de 0.5:
0.5 ^ 4 = 0.0625
0.0625 * 2073600 = 129600 pixels
Si la cantidad de píxeles ahorrados es mayor que este umbral, se activa el recorte (scissor).