Up to date
This page is up to date for Godot 4.2.
If you still find outdated information, please open an issue.
Оптимізація Центрального Процесора¶
Вимірювання продуктивності¶
We have to know where the "bottlenecks" are to know how to speed up our program. Bottlenecks are the slowest parts of the program that limit the rate that everything can progress. Focusing on bottlenecks allows us to concentrate our efforts on optimizing the areas which will give us the greatest speed improvement, instead of spending a lot of time optimizing functions that will lead to small performance improvements.
Для ЦП найпростіший спосіб виявити вузькі місця – це використовувати профайлер.
Профайлери ЦП¶
Профайлери працюють разом із вашою програмою та проводять вимірювання часу, щоб визначити, яку частку часу витрачається на кожну функцію.
Godot IDE має вбудований профайлер. Він не запускається щоразу, коли ви запускаєте проект: його потрібно запускати та зупиняти вручну. Це тому, що, як і більшість профайлерів, запис цих вимірювань часу може значно уповільнити ваш проект.
Після роботи профайлера, ви можете переглянути результати за кадр.
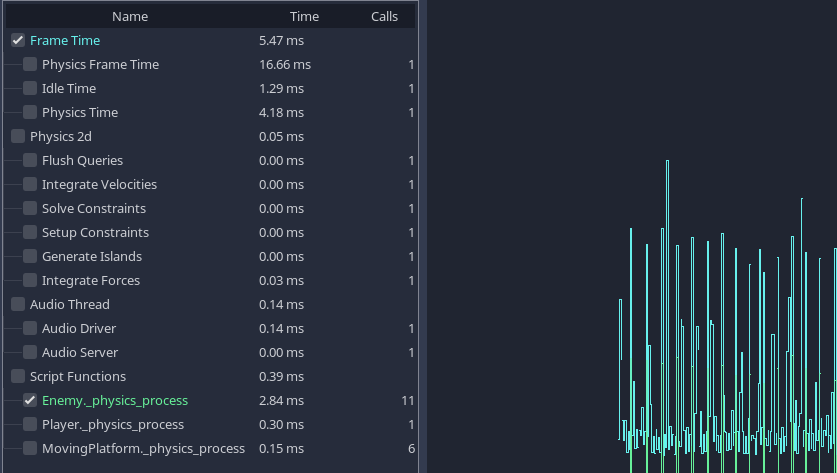
Результати профайлера для одного з демонстраційних проектів.¶
Примітка
Ми можемо побачити вартість вбудованих процесів, таких як фізика та аудіо, а також бачимо внизу вартість наших власних функцій зі скрипту.
Час, витрачений на очікування різних вбудованих серверів, може не враховуватися в профайлерах. Це відома помилка.
Коли проект працює повільно, ви часто зможете побачите очевидну функцію, або процес, що займає набагато більше часу, ніж інші. Це ваше основне вузьке місце, і ви зазвичай зможете збільшити швидкість, оптимізуючи цю область.
Щоб отримати додаткові відомості про використання вбудованого профайлера Godot, див. Debugger panel.
Зовнішні профайлери¶
Хоча профайлер Godot IDE дуже зручний і корисний, іноді вам потрібна більша потужність і можливість профілювання самого вихідного коду рушія Godot.
You can use a number of third-party C++ profilers to do this.
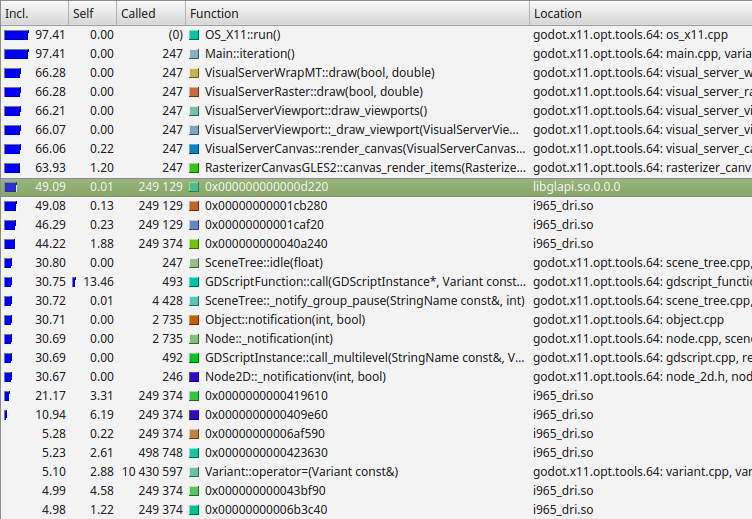
Приклад результатів від Callgrind, який є частиною Valgrind.¶
Зліва Callgrind перераховує відсоток часу у функції та її нащадків (включно), відсоток часу, проведеного в самій функції, за винятком дочірніх функцій (Self), кількість викликів функції, назву функції, а також файл, або модуль.
In this example, we can see nearly all time is spent under the
Main::iteration() function. This is the master function in the Godot source
code that is called repeatedly. It causes frames to be drawn, physics ticks to
be simulated, and nodes and scripts to be updated. A large proportion of the
time is spent in the functions to render a canvas (66%), because this example
uses a 2D benchmark. Below this, we see that almost 50% of the time is spent
outside Godot code in libglapi and i965_dri (the graphics driver).
This tells us the a large proportion of CPU time is being spent in the
graphics driver.
Насправді це чудовий приклад, тому що в ідеальному світі лише дуже мала частина часу витрачалася б на графічний драйвер. Це вказує на те, що існує проблема із занадто великою кількістю зв’язку та роботи, що виконується в графічному API. Це специфічне профілювання призвело до розробки 2D пакетної обробки, яка значно прискорює 2D-рендерінг, зменшуючи вузькі місця в цій області.
Функції визначення часу вручну¶
Ще одна зручна техніка, особливо коли ви визначили вузьке місце за допомогою профайлера, полягає в тому, щоб вручну визначити час роботи функції або області коду, що тестується. Специфіка залежить від мови, але в GDScript ви повинні зробити наступне:
var time_start = OS.get_ticks_usec()
# Your function you want to time
update_enemies()
var time_end = OS.get_ticks_usec()
print("update_enemies() took %d microseconds" % time_end - time_start)
Під час ручного визначення часу зазвичай доцільно запускати функцію багато разів (1000 і більше), а не лише один раз (якщо це не дуже повільна функція). Причина цього полягає в тому, що таймери часто мають обмежену точність. Крім того, процесори плануватимуть процеси випадковим чином. Тому середнє значення за серією прогонів є більш точним, ніж одне вимірювання.
Намагаючись оптимізувати функції, обов'язково проводьте повторне профілювання або замір часу виконання. Так ви зрозумієте, чи працює оптимізація (чи ні).
Кеші¶
Кеш-пам'ять процесора - це ще одна річ, про яку слід пам'ятати, особливо коли порівнюються результати часу виконання двох різних версій функції. Результати можуть сильно залежати від того, чи є дані в кеші процесора чи ні. Процесори не завантажують дані безпосередньо з системної оперативної пам'яті, навіть якщо вона величезна порівняно з кешем процесора (кілька гігабайт замість кількох мегабайт). Це пов'язано з тим, що системна оперативна пам'ять дуже повільна для доступу. Замість цього процесори завантажують дані з меншого, швидшого банку пам'яті, який називається кеш. Завантаження даних з кешу відбувається дуже швидко, але кожного разу, коли ви намагаєтеся завантажити адресу пам'яті, яка не зберігається в кеші, кеш повинен звертатися до основної пам'яті і повільно завантажувати дані. Ця затримка може призвести до тривалого простою процесора і називається "промахом кешу".
Це означає, що при першому запуску функції вона може працювати повільно, оскільки дані не знаходяться в кеші процесора. Вдруге і пізніше вона може працювати набагато швидше, оскільки дані знаходяться в кеші. Через це завжди використовуйте середні значення при визначенні часу і пам'ятайте про вплив кешу.
Розуміння кешування також має вирішальне значення для оптимізації процесора. Якщо у вас є алгоритм (підпрограма), який завантажує невеликі біти даних з випадково розподілених ділянок оперативної пам'яті, це може призвести до великої кількості промахів кешу, і процесор більшу частину часу буде чекати на дані замість того, щоб виконувати будь-яку роботу. Натомість, якщо ви можете зробити доступ до даних локалізованим, або, ще краще, звертатися до пам'яті лінійно (як до безперервного списку), то кеш працюватиме оптимально, а процесор зможе працювати якомога швидше.
Godot usually takes care of such low-level details for you. For example, the Server APIs make sure data is optimized for caching already for things like rendering and physics. Still, you should be especially aware of caching when writing GDExtensions.
Мови¶
Godot підтримує кілька різних мов, і варто пам'ятати, що тут є певні компроміси. Деякі мови призначені для простоти використання за рахунок швидкості, а інші - швидші, але з ними складніше працювати.
Вбудовані функції рушія працюють з однаковою швидкістю незалежно від обраної вами мови для написання скриптів. Якщо ваш проект виконує багато обчислень у власному коді, подумайте про перенесення цих обчислень на швидшу мову.
Скрипт¶
GDScript простим у використанні та ітераціях, і він ідеально підходить для створення багатьох типів ігор. Однак у цій мові простота використання вважається важливішою за продуктивність. Якщо вам потрібно робити важкі обчислення, подумайте про те, щоб перенести частину вашого проекту на одну з інших мов.
C#¶
C# is popular and has first-class support in Godot. It offers a good compromise between speed and ease of use. Beware of possible garbage collection pauses and leaks that can occur during gameplay, though. A common approach to workaround issues with garbage collection is to use object pooling, which is outside the scope of this guide.
Інші мови¶
Third parties provide support for several other languages, including Rust.
C++¶
Godot is written in C++. Using C++ will usually result in the fastest code. However, on a practical level, it is the most difficult to deploy to end users' machines on different platforms. Options for using C++ include GDExtensions and custom modules.
Потоки¶
Коли ви робите багато обчислень, подумайте про використання потоків, які можуть виконуватися паралельно один з одним. Сучасні процесори мають кілька ядер, кожне з яких здатне виконувати обмежений обсяг роботи. Розподіливши роботу на декілька потоків, ви зможете досягти максимальної ефективності процесора.
The disadvantage of threads is that you have to be incredibly careful. As each CPU core operates independently, they can end up trying to access the same memory at the same time. One thread can be reading to a variable while another is writing: this is called a race condition. Before you use threads, make sure you understand the dangers and how to try and prevent these race conditions. Threads can make debugging considerably more difficult.
Для отримання додаткової інформації про потоки див. Використання кількох потоків.
Дерево Сцен¶
Although Nodes are an incredibly powerful and versatile concept, be aware that
every node has a cost. Built-in functions such as _process() and
_physics_process() propagate through the tree. This housekeeping can reduce
performance when you have a very large numbers of nodes (how many exactly
depends on the target platform and can range from thousands to tens of
thousands so ensure that you profile performance on all target platforms
during development).
Кожен вузол обробляється окремо у візуалізаторі Godot. Тому менша кількість вузлів з більшою кількістю даних у кожному з них може призвести до кращої продуктивності.
Однією з особливостей Дерева Сцен є те, що іноді ви можете отримати набагато кращу продуктивність, видаливши вузли з Дерева Сцен, а не призупинивши, чи приховавши, їх. Вам не обов'язково видаляти відокремлений вузол. Ви можете, наприклад, зберегти посилання на вузол, вилучити його з дерева сцен за допомогою Node.remove_child(вузол), а потім знову приєднати його за допомогою Node.add_child(вузол). Це може бути дуже корисно, наприклад, для додавання та видалення областей у грі.
Ви можете взагалі відмовитися від Дерева Сцен, скориставшись серверними API. Докладнішу інформацію наведено у Оптимізація за допомогою серверів.
Фізика¶
У деяких ситуаціях вузьким місцем може стати фізика. Особливо це стосується складних світів і великої кількості фізичних об'єктів.
Ось кілька прийомів для прискорення фізики:
Спробуйте використовувати спрощені версії геометрії для форм зіткнення. Часто це буде непомітно для кінцевих користувачів, але може значно підвищити продуктивність.
Спробуйте видаляти об'єкти з фізикою, коли вони знаходяться поза зоною видимості/за межами поточної області, або використовувати фізичні об'єкти повторно (наприклад, ви дозволите 8 монстрів на область, і використаєте їх повторно).
Іншим важливим аспектом фізики є частота оновлення фізики. У деяких іграх ви можете значно зменшити частоту оновлення фізики, і замість того, щоб, наприклад, оновлювати фізику 60 разів на секунду, ви можете оновлювати її лише 30, або навіть 20, разів на секунду. Це може значно зменшити навантаження на процесор.
Недоліком зміни частоти оновлення фізики є те, що ви можете отримати ривкові рухи, або тремтіння, коли частота оновлення фізики не відповідає частоті візуалізації кадрів на секунду. Крім того, зменшення частоти оновлення фізики може призвести до збільшення затримки введення. У більшості ігор, де гравець рухається у реальному часі, рекомендується дотримуватися частоти оновлення фізики за замовчуванням (60 Гц).
Вирішенням проблеми тремтіння є використання інтерполяції з фіксованим кроком, яка передбачає згладжування позицій та обертань зображуваного кадру протягом декількох кадрів, щоб відповідати фізиці. Ви можете реалізувати її самостійно або використати сторонній аддон<https://github.com/lawnjelly/smoothing-addon> __. З точки зору продуктивності, інтерполяція є дуже дешевою операцією порівняно зі збільшенням частоти оновлення фізики. Вона на порядки швидша, тож це може дати значний виграш у продуктивності, а також зменшити тремтіння.