Up to date
This page is up to date for Godot 4.2.
If you still find outdated information, please open an issue.
Optimización de CPU¶
Medición de desempeño¶
We have to know where the "bottlenecks" are to know how to speed up our program. Bottlenecks are the slowest parts of the program that limit the rate that everything can progress. Focusing on bottlenecks allows us to concentrate our efforts on optimizing the areas which will give us the greatest speed improvement, instead of spending a lot of time optimizing functions that will lead to small performance improvements.
Para identificar los cuellos de botella en la CPU, la forma más sencilla es utilizar un perfilador (profiler).
Perfiladores de CPU¶
Los perfiladores se ejecutan junto con tu programa y toman mediciones de tiempo para determinar qué proporción del tiempo se gasta en cada función.
El IDE de Godot tiene convenientemente un perfilador integrado. No se ejecuta automáticamente cada vez que inicias tu proyecto, sino que debe ser iniciado y detenido manualmente. Esto se debe a que, al igual que la mayoría de los perfiladores, grabar estas mediciones de tiempo puede ralentizar significativamente tu proyecto.
Después de realizar el perfilado, puedes revisar los resultados para un fotograma específico.
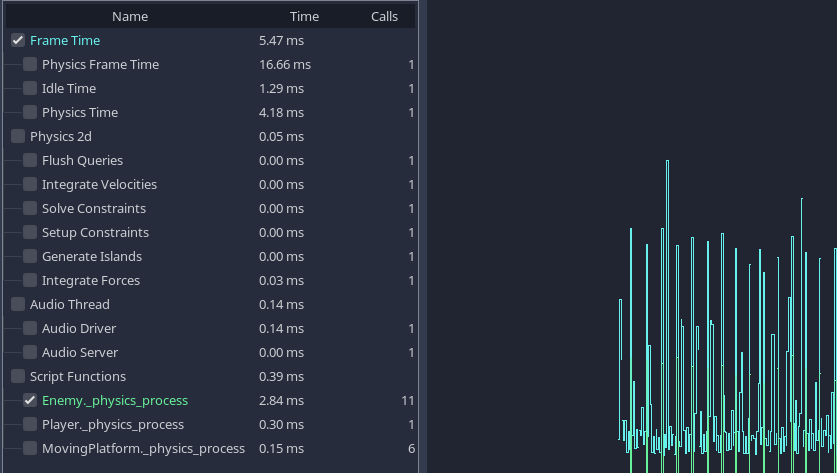
Resultados de un perfil de un de los proyectos demo.¶
Nota
Podemos ver el costo de los procesos integrados, como la física y el audio, así como el costo de nuestras propias funciones de script en la parte inferior.
El tiempo que se pasa esperando a varios servidores incorporados puede no contabilizarse en los perfiladores. Este es un error conocido.
Cuando un proyecto se ejecuta lentamente, a menudo se puede identificar una función o proceso específico que está consumiendo mucho más tiempo que los demás. Este es tu principal cuello de botella y generalmente puedes aumentar la velocidad optimizando esta área.
Para obtener más información sobre el uso del generador de perfiles integrado de Godot, consulte Panel del depurador.
Perfiladores externos¶
Aunque el perfilador integrado en el IDE de Godot es muy conveniente y útil, a veces se necesita más potencia y la capacidad de perfilar el código fuente del motor de Godot en sí mismo.
You can use a number of third-party C++ profilers to do this.
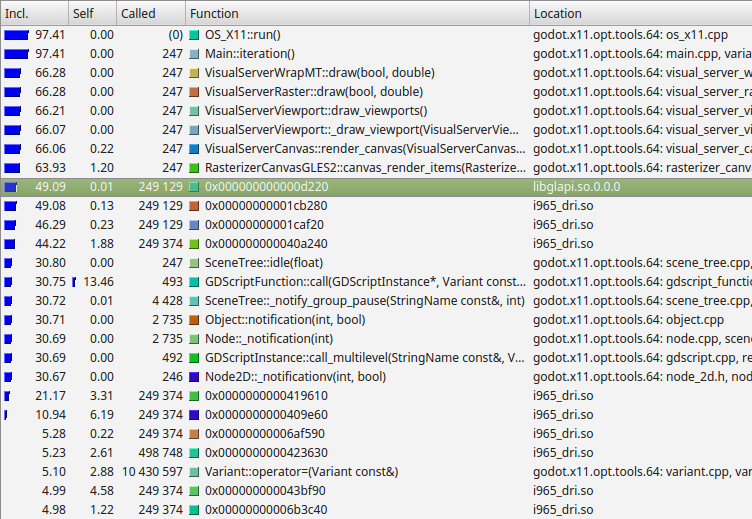
Ejemplo de resultados de Callgrind, que es parte de Valgrind.¶
Desde la izquierda, Callgrind enumera el porcentaje de tiempo dentro de una función y sus funciones hijas (Inclusivo), el porcentaje de tiempo gastado dentro de la propia función, excluyendo las funciones hijas (Propio), el número de veces que se llama a la función, el nombre de la función y el archivo o módulo correspondiente.
In this example, we can see nearly all time is spent under the
Main::iteration() function. This is the master function in the Godot source
code that is called repeatedly. It causes frames to be drawn, physics ticks to
be simulated, and nodes and scripts to be updated. A large proportion of the
time is spent in the functions to render a canvas (66%), because this example
uses a 2D benchmark. Below this, we see that almost 50% of the time is spent
outside Godot code in libglapi and i965_dri (the graphics driver).
This tells us the a large proportion of CPU time is being spent in the
graphics driver.
Este es realmente un excelente ejemplo porque, en un mundo ideal, solo una pequeña proporción de tiempo se gastaría en el controlador gráfico. Esto es una indicación de que hay un problema con una comunicación y trabajo excesivos que se realizan en la API gráfica. Este perfilado específico condujo al desarrollo de la agrupación en 2D, lo cual acelera considerablemente el renderizado en 2D al reducir los cuellos de botella en esta área.
Funciones de sincronización manual¶
Otra técnica útil, especialmente una vez que hayas identificado el cuello de botella utilizando un perfilador, es medir manualmente el tiempo de ejecución de una función o área bajo prueba. Los detalles específicos pueden variar según el lenguaje, pero en GDScript, podrías hacer lo siguiente:
var time_start = Time.get_ticks_usec()
# Your function you want to time
update_enemies()
var time_end = Time.get_ticks_usec()
print("update_enemies() took %d microseconds" % time_end - time_start)
Cuando mides manualmente el tiempo de las funciones, generalmente es una buena idea ejecutar la función muchas veces (1,000 o más veces), en lugar de solo una vez (a menos que sea una función muy lenta). La razón para hacer esto es que los temporizadores a menudo tienen una precisión limitada. Además, las CPUs programan los procesos de manera aleatoria. Por lo tanto, un promedio de una serie de ejecuciones es más preciso que una sola medición.
A medida que intentes optimizar las funciones, asegúrate de perfilar o medir el tiempo de manera repetida a medida que avanzas. Esto te brindará una retroalimentación crucial para determinar si la optimización está funcionando (o no).
Cachés¶
Las caches de la CPU son unas cosas a las que hay que tener muy en cuenta, especialmente cuando se comparan los resultados de las medidas de tiempo de dos versiones diferentes de una función. Los resultados pueden ser muy dependientes del hecho de que los datos estén en la cache de la CPU o no. Las CPUs no cargan los datos directamente desde la RAM del sistema, aunque esta sea enorme en comparación de la cache de la CPU (varios gigabytes en vez de algunos megabytes). Esto es así debido a que el acceso a la RAM del sistema es muy lento. En su lugar, las CPUs cargan los datos banco de memoria pequeño y rápido llamado cache. Cargar datos desde la cache es muy rápido, pero cada vez que intentas acceder a una dirección de memoria que no esta almacenada en la cache, la misma tendrá que ir a la memoria principal y lentamente cargar algunos datos. Esta demora puede resultar en que la CPU se quede inactiva por un tiempo largo, lo que es conocido como "cache miss".
Esto significa que la primera vez que ejecutas una función, puede ser lenta porque los datos no están en la memoria caché de la CPU. Las veces siguientes, puede ejecutarse mucho más rápido porque los datos están en la caché. Debido a esto, siempre utiliza promedios al medir el tiempo y ten en cuenta los efectos de la memoria caché.
Comprender el funcionamiento de la memoria caché también es crucial para la optimización de la CPU. Si tienes un algoritmo (rutina) que carga pequeñas partes de datos desde áreas aleatoriamente dispersas en la memoria principal, esto puede resultar en muchas "faltas de caché" (cache misses) y, en muchos casos, la CPU estará esperando los datos en lugar de realizar trabajo. En cambio, si puedes hacer que los accesos a los datos sean localizados o, aún mejor, acceder a la memoria de manera lineal (como una lista continua), entonces la caché funcionará de manera óptima y la CPU podrá trabajar tan rápido como sea posible.
Godot usually takes care of such low-level details for you. For example, the Server APIs make sure data is optimized for caching already for things like rendering and physics. Still, you should be especially aware of caching when writing GDExtensions.
Idiomas¶
Es cierto que Godot admite varios lenguajes diferentes, y es importante tener en cuenta que existen compensaciones involucradas. Algunos lenguajes están diseñados para ser fáciles de usar a costa de la velocidad, mientras que otros son más rápidos pero más difíciles de trabajar.
Las funciones incorporadas del motor se ejecutan a la misma velocidad sin importar el lenguaje de script que elijas. Si tu proyecto realiza muchas operaciones de cálculo en su propio código, considera trasladar esas operaciones a un lenguaje más rápido.
GDScript¶
GDScript está diseñado para ser fácil de usar y permite un proceso de iteración rápido, lo que lo hace ideal para crear diversos tipos de juegos. Sin embargo, en este lenguaje, la facilidad de uso se considera más importante que el rendimiento. Si necesitas realizar cálculos intensivos, considera trasladar parte de tu proyecto a alguno de los otros lenguajes disponibles en Godot.
C#¶
C# is popular and has first-class support in Godot. It offers a good compromise between speed and ease of use. Beware of possible garbage collection pauses and leaks that can occur during gameplay, though. A common approach to workaround issues with garbage collection is to use object pooling, which is outside the scope of this guide.
Otros idiomas¶
Third parties provide support for several other languages, including Rust.
C++¶
Godot is written in C++. Using C++ will usually result in the fastest code. However, on a practical level, it is the most difficult to deploy to end users' machines on different platforms. Options for using C++ include GDExtensions and custom modules.
Hilos¶
Considera utilizar hilos (threads) cuando realices una gran cantidad de cálculos que pueden ejecutarse en paralelo. Los procesadores modernos tienen múltiples núcleos, cada uno capaz de realizar una cantidad limitada de trabajo. Al distribuir el trabajo en múltiples hilos, puedes acercarte más a la máxima eficiencia de la CPU.
The disadvantage of threads is that you have to be incredibly careful. As each CPU core operates independently, they can end up trying to access the same memory at the same time. One thread can be reading to a variable while another is writing: this is called a race condition. Before you use threads, make sure you understand the dangers and how to try and prevent these race conditions. Threads can make debugging considerably more difficult.
Para obtener más información sobre subprocesos, consulte Usando múltiples hilos.
Árbol de Escenas¶
Although Nodes are an incredibly powerful and versatile concept, be aware that
every node has a cost. Built-in functions such as _process() and
_physics_process() propagate through the tree. This housekeeping can reduce
performance when you have a very large numbers of nodes (how many exactly
depends on the target platform and can range from thousands to tens of
thousands so ensure that you profile performance on all target platforms
during development).
Cada nodo se maneja de forma individual en el motor de renderizado de Godot. Por lo tanto, tener un menor número de nodos con más contenido en cada uno puede conducir a un mejor rendimiento.
Una particularidad del SceneTree es que a veces se puede obtener un mejor rendimiento al eliminar nodos del SceneTree en lugar de pausarlos u ocultarlos. No es necesario eliminar un nodo que ha sido desvinculado. Por ejemplo, puedes mantener una referencia a un nodo, desvincularlo del SceneTree utilizando Node.remove_child(node), y luego volver a vincularlo más adelante utilizando Node.add_child(node). Esto puede ser muy útil para agregar y eliminar áreas de un juego, por ejemplo.
Es posible evitar el uso del SceneTree por completo utilizando las API de los servidores (Server APIs). Para obtener más información, consulta la documentación sobre cómo utilizar los servidores (Optimización usando Servidores).
Física¶
En algunas situaciones, la física puede convertirse en un cuello de botella. Esto ocurre especialmente en mundos complejos y con un gran número de objetos físicos.
Aquí hay algunas técnicas para acelerar la física:
Intenta utilizar versiones simplificadas de la geometría renderizada para las formas de colisión. A menudo, esto no será perceptible para los usuarios finales, pero puede aumentar considerablemente el rendimiento.
Intenta eliminar los objetos de la física cuando estén fuera de la vista o fuera del área actual, o reutilizar los objetos físicos. Por ejemplo, (podrías permitir un máximo de 8 monstruos por área y reutilizarlos).
Otro aspecto crucial de la física es la tasa de actualización de los ticks físicos. En algunos juegos, puedes reducir considerablemente la tasa de ticks, en lugar de, por ejemplo, actualizar la física 60 veces por segundo, puedes hacerlo solo 30 o incluso 20 veces por segundo. Esto puede reducir considerablemente la carga de la CPU.
El inconveniente de cambiar la tasa de ticks de la física es que puedes experimentar movimientos bruscos o temblores cuando la tasa de actualización de la física no coincide con los cuadros por segundo que se renderizan. Además, disminuir la tasa de ticks de la física aumentará la latencia de entrada. Se recomienda mantener la tasa de ticks de la física predeterminada (60 Hz) en la mayoría de los juegos que presentan movimientos en tiempo real del jugador.
La solución para el temblor es utilizar la "interpolación de pasos de tiempo fijos" (fixed timestep interpolation), que implica suavizar las posiciones y rotaciones renderizadas a lo largo de varios cuadros para que coincidan con la física. Puedes implementar esto por ti mismo o utilizar un third-party addon. En cuanto al rendimiento, la interpolación es una operación muy económica en comparación con la ejecución de un tick de física. Es varias órdenes de magnitud más rápida, por lo que puede suponer un gran beneficio en rendimiento al tiempo que reduce el temblor.