Up to date
This page is up to date for Godot 4.2.
If you still find outdated information, please open an issue.
CPU 优化¶
测量性能¶
We have to know where the "bottlenecks" are to know how to speed up our program. Bottlenecks are the slowest parts of the program that limit the rate that everything can progress. Focusing on bottlenecks allows us to concentrate our efforts on optimizing the areas which will give us the greatest speed improvement, instead of spending a lot of time optimizing functions that will lead to small performance improvements.
对于 CPU 来说,找出瓶颈的最简单方法就是使用性能剖析器。
CPU 分析器¶
剖析器与你的程序一起运行, 并进行时间测量, 以计算出每个功能所花费的时间比例.
Godot集成开发环境有一个方便的内置剖析器. 它不会在每次启动项目时运行: 必须手动启动和停止. 这是因为, 与大多数剖析器一样, 记录这些时序测量会大大减慢你的项目速度.
剖析后, 你可以回看一帧的结果.
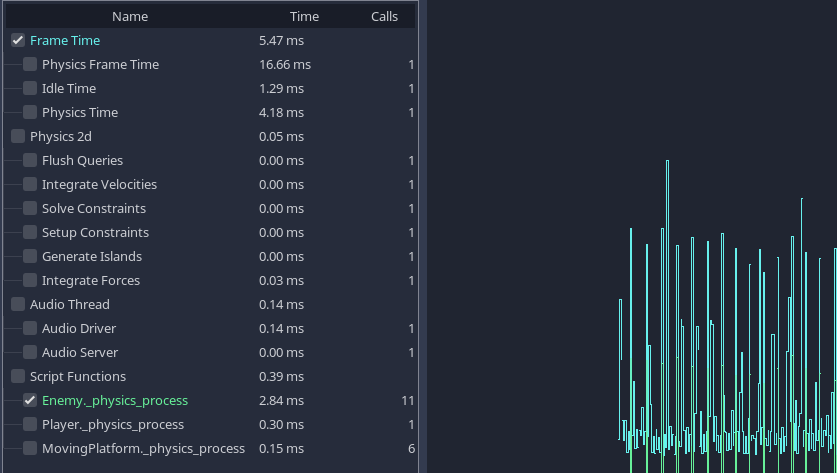
其中一个演示项目的简介结果.¶
备注
我们可以看到物理, 音频等内置流程的消耗, 也可以在底部看到自己脚本功能的消耗.
等待各种内置服务器的时间可能不会被计算在剖析器中. 这是一个已知的错误.
当一个项目运行缓慢时, 你经常会看到一个明显的功能或流程比其他功能或流程花费更多的时间. 这是你的主要瓶颈, 你通常可以通过优化这个领域来提高速度.
有关使用Godot内置分析器的更多信息, 请参阅: 调试器面板.
外部分析器¶
虽然Godot IDE剖析器非常方便有用, 但有时你需要更强大的功能, 以及对Godot引擎源代码本身进行剖析的能力.
你可以 使用若干个第三方 C++ 分析器 来实现。
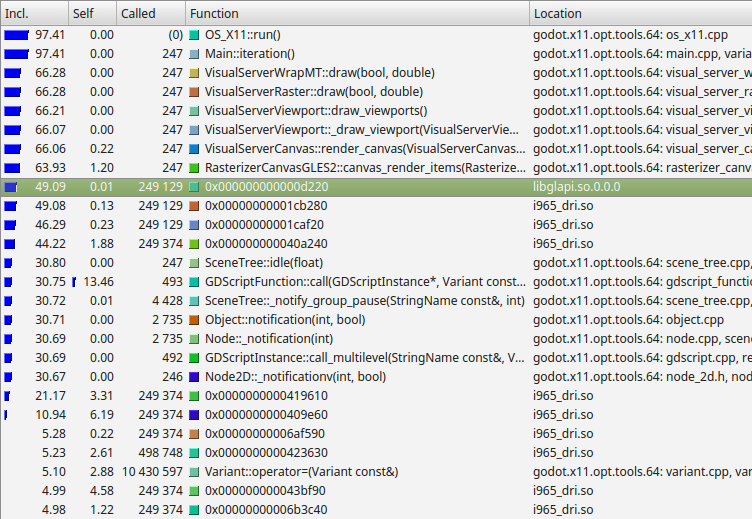
例子结果来自Callgrind, 这是Valgrind的一部分.¶
从左边开始,Callgrind正在列出函数及其子函数内的时间百分比(Inclusive), 函数本身(不包括子函数)内的时间百分比(Self), 函数被调用的次数, 函数名称以及文件或模块.
In this example, we can see nearly all time is spent under the
Main::iteration() function. This is the master function in the Godot source
code that is called repeatedly. It causes frames to be drawn, physics ticks to
be simulated, and nodes and scripts to be updated. A large proportion of the
time is spent in the functions to render a canvas (66%), because this example
uses a 2D benchmark. Below this, we see that almost 50% of the time is spent
outside Godot code in libglapi and i965_dri (the graphics driver).
This tells us the a large proportion of CPU time is being spent in the
graphics driver.
这其实是一个很好的例子, 因为在理想的世界里, 只有很小一部分时间会花在图形驱动上. 这说明存在一个问题, 就是在图形API中进行了太多的交流和工作. 这种特殊的剖析导致了2D批处理的发展, 通过减少这方面的瓶颈, 大大加快了2D渲染的速度.
手动计时函数¶
另一个方便的技术, 特别是当你使用分析器确定了瓶颈后, 就是手动为功能或被测区域计时. 具体细节因语言而异, 但在GDScript中, 你可以做如下操作:
var time_start = Time.get_ticks_usec()
# Your function you want to time
update_enemies()
var time_end = Time.get_ticks_usec()
print("update_enemies() took %d microseconds" % time_end - time_start)
当手动为函数计时时, 通常最好是多次(1000次或更多次)运行该函数, 而不是只运行一次(除非是非常慢的函数). 这样做的原因是, 定时器的精度往往有限. 此外,CPU会以一种无序的方式调度进程. 因此, 一系列运行的平均值比单次测量更准确.
当你尝试优化功能时, 一定要反复对它们进行剖析或计时. 这将为你提供关键的反馈, 说明优化是否有效(或无效).
缓存¶
CPU缓存是另外一个需要特别注意的东西, 特别是在比较一个函数的两个不同版本的时序结果时. 其结果可能高度依赖于数据是否在CPU缓存中.CPU不会直接从系统RAM中加载数据, 尽管它与CPU缓存相比非常巨大(几千兆字节而不是几兆字节). 这是因为系统RAM的访问速度非常慢. 相反,CPU从一个较小, 较快的内存库中加载数据, 称为cache. 从缓存中加载数据的速度非常快, 但每次你试图加载一个没有存储在缓存中的内存地址时, 缓存必须前往主内存并缓慢地加载一些数据. 这种延迟会导致CPU长时间闲置, 被称为 "cache miss".
这意味着, 第一次运行一个函数时, 由于数据不在CPU缓存中, 它可能运行得很慢. 第二次和以后的时间, 可能运行得更快, 因为数据在缓存中. 由于这个原因, 在计时时一定要使用平均数, 并且要注意缓存的影响.
了解缓存对于CPU优化也是至关重要的. 如果你有一个算法(例程), 从主内存随机分布的区域加载小数据位, 这可能会导致大量的缓存失误, 很多时候,CPU会在附近等待数据, 而不是做别的工作. 相反, 如果你能使你的数据访问本地化, 或者更好的是以线性方式访问内存(像一个连续的列表), 那么缓存将以最佳方式工作,CPU将能够尽可能快地工作.
Godot usually takes care of such low-level details for you. For example, the Server APIs make sure data is optimized for caching already for things like rendering and physics. Still, you should be especially aware of caching when writing GDExtensions.
语言¶
Godot支持多种不同的语言, 值得注意的是, 其中有一些折衷. 有些语言是以速度为代价而设计的, 便于使用, 而另一些语言速度更快, 但更难使用.
无论你选择哪种脚本语言, 内置的引擎函数都以同样的速度运行. 如果你的项目在自己的代码中进行了大量的计算, 可以考虑将这些计算转移到更快的语言中.
GDScript¶
GDScript 被设计成易于使用和迭代的语言, 是制作多种类型游戏的理想选择. 然而, 在这种语言中, 易用性被认为比性能更重要. 如果你需要进行繁重的计算, 请考虑将你的一些项目转移到其他语言中.
C#¶
C# is popular and has first-class support in Godot. It offers a good compromise between speed and ease of use. Beware of possible garbage collection pauses and leaks that can occur during gameplay, though. A common approach to workaround issues with garbage collection is to use object pooling, which is outside the scope of this guide.
其他语言¶
Third parties provide support for several other languages, including Rust.
C++¶
Godot 是用 C++ 编写的。使用 C++ 通常会产生最快的代码。然而,在实际层面上,部署到不同平台的最终用户机器上是最困难的。使用 C++ 的选项包括 GDExtensions 和 自定义模块。
线程¶
在进行大量的计算时, 考虑使用线程, 这些计算可以相互并行运行. 现代CPU有多个核心, 每个核心能做的工作量有限. 通过将工作分散在多个线程上, 你可以进一步向CPU的峰值效率迈进.
The disadvantage of threads is that you have to be incredibly careful. As each CPU core operates independently, they can end up trying to access the same memory at the same time. One thread can be reading to a variable while another is writing: this is called a race condition. Before you use threads, make sure you understand the dangers and how to try and prevent these race conditions. Threads can make debugging considerably more difficult.
有关线程的更多信息, 请参见 使用多线程.
SceneTree¶
虽然节点是一个非常强大、涉及面广泛的概念,但请注意:每个节点都是有代价的。内置函数,如 _process() 和 _physics_process() 会在节点树上遍历每个节点进行调用。当你有非常多的节点时,这种内务管理就会降低性能。(节点的数量取决于目标平台,可能从数千到数万不等,请确保在开发过程中评测所有目标平台上的性能)。
在 Godot 渲染器中,每个节点都是单独处理的。总的节点数量越少,每个节点中的节点越多,可以获得更好的性能。
SceneTree 比较奇怪的一点是:你有时可以通过从 SceneTree 中删除节点,而非暂停或隐藏节点这种方式来获得更好的性能,不一定要删除一个从场景树中分离出来的的节点。例如,你可以保留一个节点的引用,使用 Node.remove_child(node) 将该节点从场景树中分离出来,然后使用 Node.add_child(node) 将其重新加回场景树。对于在游戏中添加和删除区域,这一点十分有用。
你可以通过使用服务器API来完全避免使用 SceneTree。更多信息请参见 利用服务器进行优化 。
物理¶
在某些情况下,物理终会成为一个瓶颈,尤其是在复杂的世界和大量物理对象的情况下更是如此。
以下是一些加速物理的技巧:
尝试使用渲染简单的几何图形来处理碰撞形状,虽然在通常情况下对终端用户来说这一点并不明显,但可以大大提高性能。
尝试禁用不在视野中/在当前区域之外的物理物体的物理效果,在视野中/在当前区域之内时则给这些物理对象启用物理效果(例如,你允许每个区域有8个怪物,并允许重新启用这些怪物的物理效果)。
物理的另一个关键方面是物理刻速率。在一些游戏中,你可以大大降低物理刻率,比如说,你可以不用每秒更新物理 60 次,而只需每秒更新 30 次甚至 20 次。这样可以大大降低 CPU 的负载。
改变物理刻速率的缺点是,当物理更新速率与每秒渲染的帧数不匹配时,可能会出现抖动。另外,降低物理刻速率会增加输入延迟。建议在大多数以玩家实时移动为特色的游戏中,坚持使用默认的物理刻速率(60 Hz)。
解决抖动的方法是使用固定时间步长插值以匹配物理,该技术涉及到平滑多个帧的渲染位置和旋转等操作。你可以自己实现,或者使用第三方插件 。来实现。从性能上来说,与运行物理刻比,插值是一个非常低成本、高性能提升的操作,速度快了好几个数量级,在减少抖动的同时也带来了部分显著的性能提升。