內部算繪架構
本頁提供 Godot 4 內部算繪器設計的高階綜覽,內容不適用於舊版 Godot。
本頁旨在記錄為了最符合 Godot 的設計理念 所做的設計決策,同時也為新的算繪貢獻者提供起點。
若你有關於算繪內部原理的問題未在此解答,歡迎加入 Godot 貢獻者聊天室 的 #rendering 頻道提問。
備註
若你在理解本頁內容時遇到困難,建議先參閱 LearnOpenGL 等 OpenGL 教學資源。
現代低階 API(如 Vulkan、Direct3D 12、Metal)要能有效使用,需具備中等以上的高階 API(如 OpenGL、Direct3D 11)知識。幸好,貢獻者很少需要直接操作這些底層 API。Godot 的算繪器完全建立在 OpenGL 與 RenderingDevice 之上,後者是針對 Vulkan/Direct3D 12/Metal 的抽象層。
算繪方法
Forward+
這是一個採用*集群式*光源處理的前向算繪器(Forward Renderer)。
集群光照會以運算著色器將燈光分組到 3D 視錐體對齊的格點內。算繪時,像素會查詢其所在柵格受哪些燈光影響,僅針對這些燈光進行光照運算。
這種方法能大幅提升桌面硬體的算繪效能,但在行動裝置上效率則較低。
行動裝置
這是一個前向算繪器,採用傳統的單通道光照方法。在內部稱為 Forward Mobile。
本方法主要針對行動平臺設計,但同樣可於桌面平臺執行。其針對行動 GPU 進行優化,由於行動 GPU 在耗電、散熱與資料頻寬等條件和桌面 GPU 差異極大,因此對計算著色器支援通常有限甚至完全不支援。因此,行動裝置的算繪器僅採用光柵(頂點/片段)著色器。
行動 GPU 不同於桌面 GPU,會採用*基於圖塊(Tile-based)*的算繪方式。整張畫面不是一次處理,而是分割為可放入 GPU 內部高速記憶體的小圖塊。每個圖塊獨立算繪後再寫入目標紋理。這過程由圖形驅動自動完成。
這會對傳統算繪流程帶來瓶頸。桌面算繪通常先處理不透明幾何、再處理背景、再繪製透明物件,最後做後處理。每個步驟都必須將目前結果讀入圖塊記憶體、處理完再寫回。每個階段都需等所有圖塊完成後方可進入下一步。
行動算繪器的第一個重要改變,是不再使用桌面算繪常見的 RGBA16F 紋理格式,而改用 R10G10B10A2 UNORM 紋理格式。這不僅將頻寬需求減半,也因行動硬體多針對 32 位元格式做優化,帶來更多效能提升。其代價是顏色資料精度與最大值下降,使行動端 HDR 能力受限。
第二個重要改變是盡可能使用子通道(sub-pass)。這讓我們能在每個圖塊內一次完成所有算繪步驟,節省每階段之間頻繁讀寫圖塊的開銷。使用子通道的限制在於無法跨圖塊讀取相鄰像素,只能於單一圖塊範圍內運算。
子通道的這項限制,導致無法高效實作輝光、景深等效果。同樣地,若需讀取畫面紋理或深度紋理,也必須將算繪結果完整寫出,限制了子通道的應用。當這些功能啟用時,會混合使用子通道與一般通道,並導致明顯效能損失。
在桌面平臺,使用子通道對效能影響不大。但對於簡單場景,這個方法因複雜度低、頻寬需求小,仍可勝過 Forward+。在低階 GPU、整合型顯示晶片或 VR 應用上尤為明顯。
由於著重支援低階裝置,本方法不支援 SDFGI、體積霧和霧體積 等高階算繪功能,亦不支援多種後期處理效果。
相容性
備註
這是在使用 OpenGL 驅動時唯一可用的算繪方法。若使用 Vulkan、Direct3D 12 或 Metal 則不支援此方法。
這是一個傳統(非集群)的前向算繪器,內部稱為 GL Compatibility。其主要目的是支援不支援 Vulkan 的舊 GPU,但在新硬體上效率同樣不錯。特別是針對舊型與低階行動裝置做了優化,許多優化也適用於舊型或低階桌面,因此也是低效能電腦的好選擇。
與行動算繪器類似,相容性算繪器在 3D 算繪時也採用 R10G10B10A2 UNORM 紋理。不同之處在於顏色會經過色調映射並以 sRGB 格式儲存,因此不支援 HDR。這樣可省略色調映射階段,並以較低位元紋理避免明顯條帶問題。
相容性算繪器對帶光源的物件採用傳統單通道前向算繪,但對有陰影的光源則使用多通道算繪。具體來說,第一個通道可繪製多個無陰影光源及一個帶陰影的 DirectionalLight3D,其後每個通道最多各可繪製一個帶陰影的 OmniLight3D、SpotLight3D 及 DirectionalLight3D。有陰影的光源會以 sRGB 空間(非線性空間)混合光照,產生與無陰影光源不同的場景外觀,設計場景時須注意此差異。
由於本方法重點在低階裝置,因此不支援高階算繪功能(甚至比行動版還少),大多數後期處理效果亦不可用。
為什麼不採用延遲算繪?
前向算繪在性能與彈性之間通常能取得較佳平衡,特別是採用集群光照時。延遲算繪雖在部分情境下更快,但其彈性較低,且需特殊處理才能支援 MSAA。由於許多非寫實風格遊戲極需 MSAA,因此 Godot 4(如同 Godot 3)選擇前向算繪。
話雖如此,前向算繪器的部分處理*確實*採用延遲算繪手法,以在合適時進行最佳化。這尤其應用於 VoxelGI 與 SDFGI。
未來有可能開發集群延遲算繪器。此渲染器適用於需極致效能而可犧牲彈性的場景。
算繪驅動
Godot 4 支援以下圖形 API:
Vulkan
這是 Godot 4 的主要驅動,開發重心多集中於此。
Vulkan 1.0 為最低需求,若可用則將額外利用 Vulkan 1.1 及 1.2 功能。Godot 使用 volk 作為 Vulkan 載入器,並透過 Vulkan Memory Allocator 來管理記憶體。
Vulkan 驅動同時支援 Forward+ 與 Mobile 算繪方法 算繪方法。
Vulkan Context 建立:
Direct3D 12 Context 建立:
Direct3D 12
如同 Vulkan,Direct3D 12 驅動僅支援現代平臺,並專為 Windows 與 Xbox 設計(Vulkan 無法直接於 Xbox 使用)。
Direct3D 12 可同時用於 Forward+ 與 Mobile 算繪方法 算繪方法。
核心著色器 與 Vulkan 算繪器共用。 著色器會透過 Mesa NIR 將 SPIR-V 轉譯為 DXIL ,詳見 更多資訊 。
此驅動仍屬實驗性,僅於 Godot 4.3 及以後版本提供。 雖然 Direct3D 12 能支援 Windows 11 上專屬的 Direct3D 功能(如視窗化最佳化與自動 HDR),但大多數專案仍建議使用 Vulkan。詳情請參閱新增 Direct3D 12 支援的「pull request <https://github.com/godotengine/godot/pull/70315>」。
Metal
Godot 提供原生 Metal 驅動,適用於所有 Apple Silicon 硬體(macOS ARM)。與透過 MoltenVK 轉譯層相比,原生 Metal 驅動效能顯著提升,特別在受限於 CPU 的情境下更為明顯。
Metal 驅動可同時使用 Forward+ 與 Mobile 算繪方法 算繪方法。
核心著色器 與 Vulkan 算繪器共用。著色器透過 SPIRV-Cross 從 GLSL 轉譯為 MSL 。
Godot 也可透過 MoltenVK 支援 Metal 算繪,當原生 Metal 不可用時(如 x86 macOS)會自動切換使用。
此驅動仍屬實驗性,僅於 Godot 4.4 及以後版本提供。 詳情請參閱新增 Metal 支援的「pull request <https://github.com/godotengine/godot/pull/88199>」。
OpenGL
此驅動採用 OpenGL ES 3.0,主要針對不支援 Vulkan 的舊型與低階裝置。桌面版則以 OpenGL 3.3 Core Profile 執行(因大多數桌面驅動不支援 OpenGL ES),Web 匯出則用 WebGL 2.0。
你也可以在桌面平臺直接使用 OpenGL ES 3.0,只要於命令列加上 --rendering-driver opengl3_es 參數,但僅支援原生 OpenGL ES 的圖形驅動(如 Mesa)。
OpenGL 驅動僅支援 相容性 算繪方法。
核心著色器 與 Vulkan 算繪器完全不同。
由於此驅動主要鎖定低階裝置,因此不支援多項進階功能。
算繪驅動/方法總覽
目前可用的算繪 API 與算繪方法組合如下:
Vulkan + Forward+(macOS 與 iOS 可選用 MoltenVK)
Vulkan + Mobile(macOS 與 iOS 可選用 MoltenVK)
Direct3D 12 + Forward+
Direct3D 12 + Mobile
Metal + Forward+
Metal + Mobile
OpenGL + 相容性(Windows 與 macOS 可選用 ANGLE)
每種組合皆有其限制與效能特性。建議你在送出 Pull Request 前,盡量於所有算繪方法下測試你的變更。
RenderingDevice 抽象層
備註
OpenGL 驅動不使用 RenderingDevice 抽象層。
為了讓現代低階圖形 API 的複雜性更易於管理,Godot 採用自有的抽象層——RenderingDevice。
這表示在為現代算繪方法撰寫程式碼時,你實際上不會直接操作 Vulkan、Direct3D 12 或 Metal API。雖然這層仍比 OpenGL 更貼近底層,但可讓算繪器的開發更容易,因為 RenderingDevice 已為你封裝許多 API 相關的細節。其抽象層級與 WebGPU 類似。
Vulkan RenderingDevice 實作:
Direct3D 12 RenderingDevice 實作:
Metal RenderingDevice 實作:
核心算繪類別架構
下圖展示 Godot 的算繪類別結構,包含 RenderingDevice 抽象層:
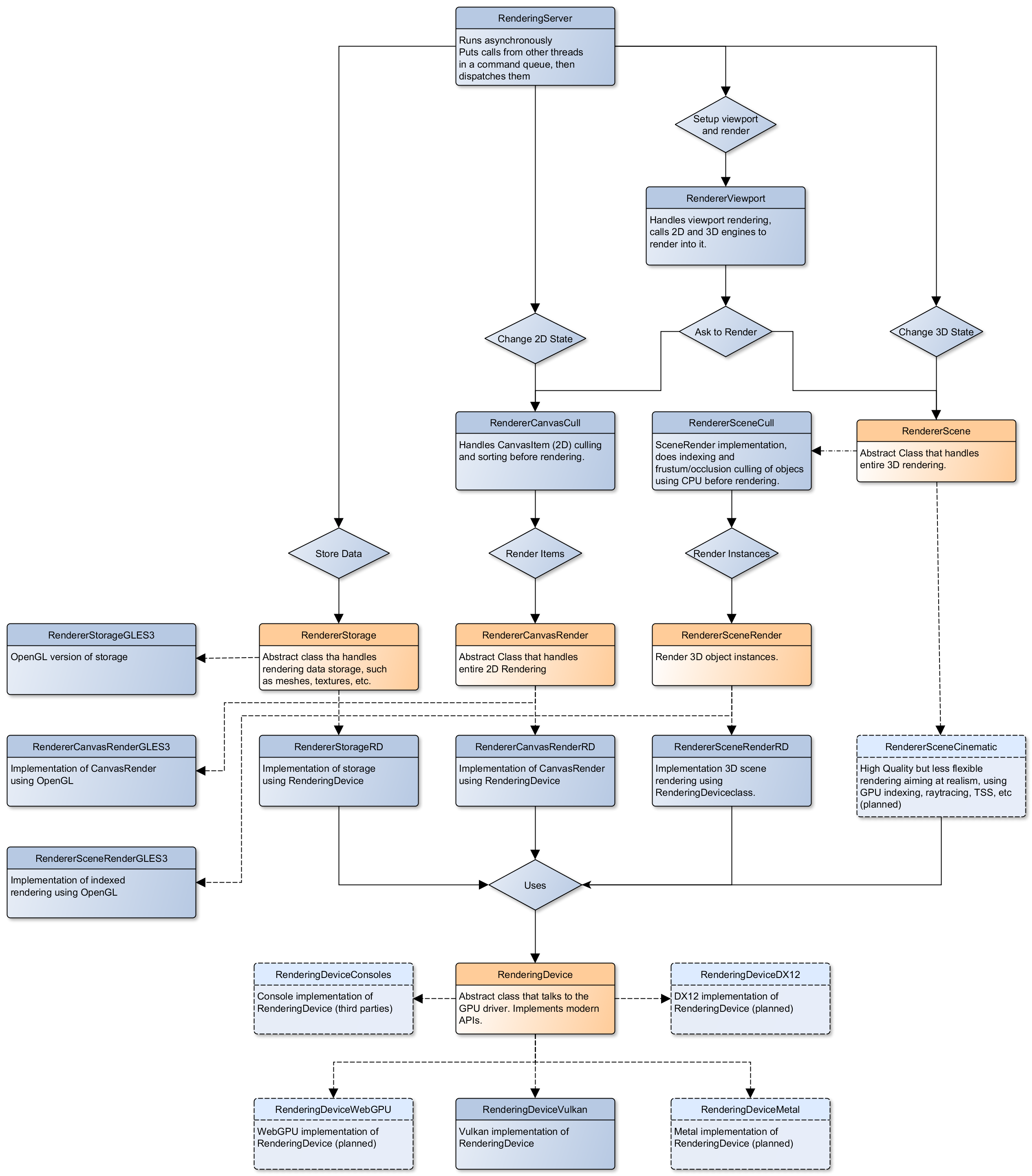
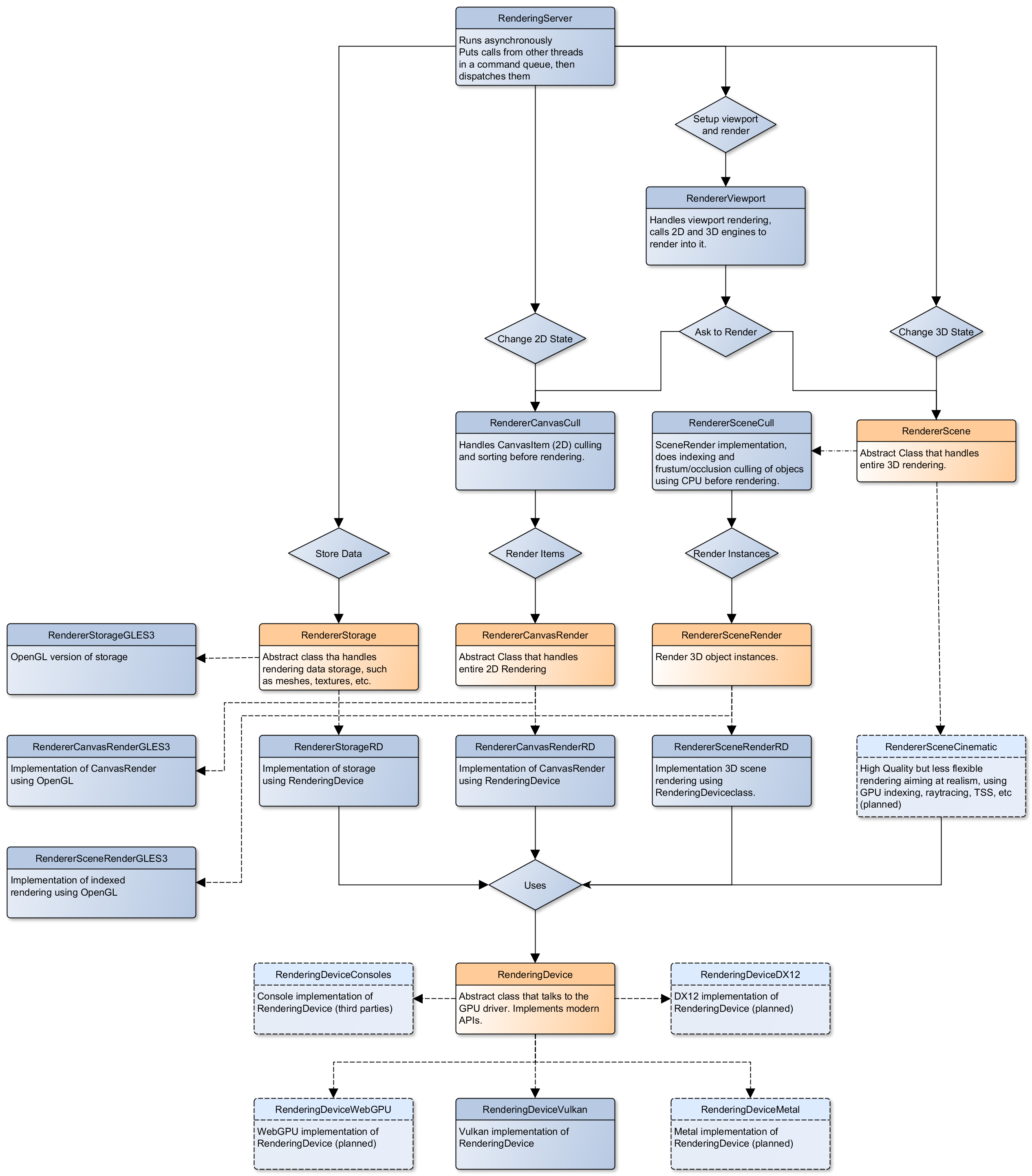{kind=link}
核心著色器
雖然 Godot 專案內的著色器多以 GLSL 為靈感的自訂語言 編寫,但核心著色器則直接以 GLSL 撰寫。
這些核心著色器於編譯時嵌入編輯器及匯出模板二進位檔。若你修改了這些 GLSL 著色器,必須重新編譯編輯器或匯出模板才能看到效果。
部分材質功能(如高度貼圖、折射與鄰近淡出)並非核心著色器的一部分,而是透過 BaseMaterial3D 的 Godot 著色器語言(非 GLSL)來實作。系統會依據啟用的功能,程序化產生對應的著色器程式碼。
按照慣例,檔名含 _inc 的著色器檔會被其他 GLSL 檔案 include,以利程式碼重用。這是利用標準 GLSL 前處理器實作。
警告
場景中所有材質(不論使用 BaseMaterial3D 或自訂著色器)都會用到核心材質著色器。因此,這些著色器必須盡量簡潔,以避免效能問題並確保著色器編譯速度。
在著色器中使用 if 分支會導致 VGPR 占用量增加,進而降低效能。即使同一幀所有像素的判斷結果都一樣,也會如此。
如在著色器中用 #if 前處理分支,會導致場景中需編譯的著色器版本數量暴增。最壞情況下,單一布林 #define 便可能使需要編譯的著色器數量加倍。有時可以用 Vulkan 的專用常數作為較快(但較有限)的替代方案。
這也代表 Godot 無論於核心著色器還是 BaseMaterial3D,要新增內建材質功能都具備高度門檻。雖然 BaseMaterial3D 可動態產生程式碼並僅針對啟用功能產生對應著色器,但專案若啟用多項功能仍會導致編譯更多著色器版本,複雜 3D 場景中會明顯增加編譯卡頓。
詳情請參閱「著色器排列問題 <https://therealmjp.github.io/posts/shader-permutations-part1/>」及「GPU 上的分支 <https://medium.com/@jasonbooth_86226/branching-on-a-gpu-18bfc83694f2>」部落格文章。
核心 GLSL 材質著色器:
Forward+:servers/rendering/renderer_rd/shaders/forward_clustered/scene_forward_clustered.glsl
Mobile:servers/rendering/renderer_rd/shaders/forward_mobile/scene_forward_mobile.glsl
Compatibility:drivers/gles3/shaders/scene.glsl
材質著色器產生:
Forward+ 與 Mobile 算繪方法的其他 GLSL 著色器:
Compatibility 算繪方法的其他 GLSL 著色器:
2D 與 3D 算繪分離
備註
以下內容僅適用於 Forward+ 與 Mobile 算繪方法,在 Compatibility 模式下不適用。若使用 Compatibility 算繪器,可透過多重 Viewport 模擬分離,或用於執行 2D 解析度縮放。
2D 與 3D 會分別算繪到不同的緩衝區,因為 Godot 的 2D 算繪是在 LDR sRGB 空間下進行,而 3D 算繪則在 HDR 線性空間中。
2D 算繪使用的色彩格式為 RGB8;若 Viewport 啟用 Transparent 屬性則為 RGBA8。3D 算繪則採用 24 位元無符號標準化整數深度緩衝區,若硬體不支援 24 位深度,則以 32 位元有符號浮點。2D 算繪則不使用深度緩衝區。
3D 解析度縮放的方式會根據選擇雙線性縮放或 FSR 1.0 縮放而有所不同。若使用雙線性縮放,不會執行特殊放大著色器,而是將視窗紋理直接拉伸,並以線性取樣器顯示(過濾直接交由硬體處理)。這可最大化雙線性 3D 縮放的效能。
當解析度或縮放比例變更時,RenderSceneBuffersRD 的 configure() 函式會重新分配 2D/3D 緩衝區。
目前尚未支援動態解析度縮放,未來 Godot 版本計畫加入此功能。
2D 與 3D 算繪緩衝區配置 C++ 程式碼:
FSR 1.0:
2D 算繪技術
2D 燈光算繪以單通道進行,以提升大量燈光下的效能。
所有算繪方法都有 2D 批次處理以提升效能,當畫面上有大量文字時尤其明顯。
2D 算繪可開啟 MSAA 以自動處理線條和多邊形的抗鋸齒,但 FXAA 不會影響 2D 算繪,因為它在 2D 算繪開始前已計算完畢。Godot 的 2D 繪製方法(如 Line2D 節點或部分 CanvasItem 的 draw_*() 方法)會以三角帶與頂點色進行自家抗鋸齒,不需倚賴 MSAA。
若使用者著色器有需求,系統會自動產生代表 Viewport 內 LightOccluder2D 節點的 2D 簽名距離場。這可用於自訂著色器的多種效果(如 2D 全域照明),也可用來計算 2D 粒子碰撞。
2D SDF 產生 GLSL 著色器:
3D 算繪技術
批次與實例化
在 Forward+ 算繪器中,會使用 Vulkan 實例化將相同的、不透明或經 Alpha 測試的物件分組算繪以提升效能(Alpha 混合的物件則永遠不會做實例化)。這雖不如靜態網格合併快,但仍可讓個別實例被獨立剔除。
燈光、貼花與反射探查算繪
備註
目前 Compatibility 算繪器尚不支援貼花(Decal)算繪。
Forward+ 算繪器採用集群光照(Clustered Lighting),可讓你任意增加燈光數量;效能主要取決於燈光在螢幕的覆蓋範圍。若無陰影且佔螢幕面積小的燈光,幾乎不會造成效能負擔。
所有算繪方法都支援同時算繪最多 8 個定向光源(若多於一個光源啟用陰影,則陰影品質會降低)。
Mobile 算繪器採用單通道光照,每個 Mesh 資源最多受 8 個 OmniLight 與 8 個 SpotLight 影響(攝影機視野內總數分別上限為 256)。這些限制為硬編碼,無法在專案設定中調整。
Compatibility 算繪器採用混合單通道+多通道光照。無陰影的燈光在單通道內算繪,有陰影的燈光則需多通道處理。這主要是為了行動裝置效能考量,因此若場景中同時存在大量投射陰影的燈光,效能不易線性擴展。建議每次攝影機視錐內僅保留少量陰影光源,且盡量分散,讓每個物件同時僅受 1~2 個陰影燈光影響。最大可見燈光數可於專案設定調整。
在這三種算繪方法中,無陰影的燈光運算成本遠低於有陰影的燈光。為了提升效能,只有當燈光本身或其半徑內物件變動時,才會更新燈光。Godot 目前尚未將靜態陰影與動態陰影算繪分離,未來版本計畫加入此功能。
Forward+ 算繪器也利用集群技術進行反射探查與貼花算繪。
陰影貼圖
Forward+ 與 Mobile 算繪方法都會使用 PCF 來處理陰影貼圖並產生柔和的半影。這兩種方法採用 vogel disk(渦格圓盤)取樣,可調整樣本數量並平順地切換陰影品質,而非固定 PCF 取樣方式。
Godot 亦支援 PCSS(百分比接近軟陰影),可產生更真實的半影效果。PCSS 僅於 Forward+ 算繪器中提供,因行動裝置效能無法負荷。PCSS 同樣使用 vogel disk 形狀的取樣核心。
此外,這兩種陰影貼圖技術都會針對每個像素旋轉取樣核心,以減輕取樣不足造成的偽影。
Compatibility 算繪器支援 DirectionalLight3D、OmniLight3D 及 SpotLight3D 的陰影貼圖。
時間性抗鋸齒(TAA)
備註
僅於 Forward+ 算繪器中提供,Mobile 與 Compatibility 算繪器不支援。
Godot 採用自訂的 TAA(時間性抗鋸齒)實作,基於 Spartan Engine <https://github.com/PanosK92/SpartanEngine> 舊版 TAA 實現。
時間性抗鋸齒需要運動向量支援。若運動向量未正確產生,則攝影機或物件移動時會出現重影。
運動向量於 GPU 端的主材質著色器中產生,會同時運行前一影格(含前一攝影機變換)與目前影格的頂點著色器,然後將其差異存於顏色緩衝區。
另外也可使用 FSR 2.2 作為升頻方案,內建自家時間性抗鋸齒演算法。Godot 的 FSR 2.2 是基於 RenderingDevice 抽象層重新實作,並非直接採用 AMD 官方程式碼。
TAA 解算:
FSR 2.2:
全域照明
備註
VoxelGI 與 SDFGI 僅於 Forward+ 算繪器中提供,Mobile 與 Compatibility 算繪器不支援。
LightmapGI 的*烘焙*僅於 Forward+ 與 Mobile 算繪器中提供,且只能於編輯器內操作(無法在匯出專案時進行)。LightmapGI 的*算繪*則由 Compatibility 算繪器支援。
Godot 支援體素式全域照明(VoxelGI)、有符號距離場全域照明(SDFGI),以及光照貼圖烘焙與算繪(LightmapGI)。這些技術可依需求同時應用。
光照貼圖烘焙會在 GPU 上以 Vulkan 運算著色器執行。GPU 版光照貼圖器實作於 LightmapperRD 類別,並繼承自 Lightmapper,故未來可新增更多光照貼圖法,也可讓 Godot 3.x 的 CPU 版光照貼圖器移植至 4.x,進而在 Compatibility 算繪器下實現光照貼圖烘焙。
全域照明(GI)核心 C++ 程式碼:
scene/3d/voxel_gi.cpp - VoxelGI 節點
editor/plugins/voxel_gi_editor_plugin.cpp - VoxelGI 節點的編輯器介面
全域照明(GI)核心 GLSL 著色器:
servers/rendering/renderer_rd/shaders/environment/voxel_gi.glsl
servers/rendering/renderer_rd/shaders/environment/voxel_gi_debug.glsl - VoxelGI 除錯繪製模式
servers/rendering/renderer_rd/shaders/environment/sdfgi_debug.glsl - SDFGI 層級除錯繪製模式
servers/rendering/renderer_rd/shaders/environment/sdfgi_debug_probes.glsl - SDFGI 探針除錯繪製模式
servers/rendering/renderer_rd/shaders/environment/sdfgi_integrate.glsl
servers/rendering/renderer_rd/shaders/environment/sdfgi_preprocess.glsl
servers/rendering/renderer_rd/shaders/environment/sdfgi_direct_light.glsl
光照貼圖器 C++ 程式碼:
scene/3d/lightmap_gi.cpp - LightmapGI 節點
editor/plugins/lightmap_gi_editor_plugin.cpp - LightmapGI 節點的編輯器介面
scene/3d/lightmapper.cpp - 抽象類別
modules/lightmapper_rd/lightmapper_rd.cpp - GPU 版光照貼圖器實作
光照貼圖器 GLSL 著色器:
景深
備註
僅於 Forward+ 與 Mobile 算繪器中提供,Compatibility 算繪器不支援。
Forward+ 與 Mobile 算繪器採用不同的景深(DOF)算繪方法,視覺效果也各異。這是為了最佳適配不同硬體的效能特性。Forward+ 採用運算著色器實作 DOF,Mobile 則以片段著色器(光柵)完成。
支援方形、六角形與圓形光斑(bokeh),順序由快至慢。開啟時間性抗鋸齒(TAA)時,也可選擇讓景深每幀抖動以改善視覺效果。
景深 C++ 程式碼:
景深 GLSL 著色器(運算用於 Forward+):
景深 GLSL 著色器(光柵用於 Mobile):
螢幕空間效果(SSAO、SSIL、SSR、SSS)
備註
僅於 Forward+ 算繪器中提供,Mobile 與 Compatibility 算繪器不支援。
Forward+ 算繪器支援螢幕空間環境光遮蔽(SSAO)、螢幕空間間接照明(SSIL)、螢幕空間反射(SSR)及次表面散射(SSS)。
SSAO 採用 Intel 的 ASSAO 實作(改寫為 Vulkan 版本)。SSIL 則以 SSAO 為基礎,提供高效能的間接照明。
當 SSAO 與 SSIL 同時啟用時,兩者部分運算資源會共用,以減少效能損耗。
預設情況下,SSAO 與 SSIL 皆以半解析度執行以提升效能。SSR 也一律採半解析度。
螢幕空間效果 C++ 程式碼:
螢幕空間環境光遮蔽 GLSL 著色器:
servers/rendering/renderer_rd/shaders/effects/ssao_blur.glsl
servers/rendering/renderer_rd/shaders/effects/ssao_interleave.glsl
servers/rendering/renderer_rd/shaders/effects/ssao_importance_map.glsl
螢幕空間間接照明 GLSL 著色器:
servers/rendering/renderer_rd/shaders/effects/ssil_blur.glsl
servers/rendering/renderer_rd/shaders/effects/ssil_interleave.glsl
servers/rendering/renderer_rd/shaders/effects/ssil_importance_map.glsl
螢幕空間反射 GLSL 著色器:
servers/rendering/renderer_rd/shaders/effects/screen_space_reflection.glsl
servers/rendering/renderer_rd/shaders/effects/screen_space_reflection_scale.glsl
servers/rendering/renderer_rd/shaders/effects/screen_space_reflection_filter.glsl
次表面散射 GLSL 著色器:
天空算繪
也參考
Godot 支援使用著色器進行天空背景算繪。輻射度貼圖(用於為 PBR 材質提供環境光及反射)會根據天空著色器自動更新。
SkyMaterial 資源(如 ProceduralSkyMaterial、PhysicalSkyMaterial、PanoramaSkyMaterial)會自動產生內建天空算繪著色器,與 BaseMaterial3D 為 3D 場景材質產生著色器機制類似。
詳細技術實作可參見「Godot 4.0 的自訂天空著色器 <https://godotengine.org/article/custom-sky-shaders-godot-4-0>」文章。
天空算繪 C++ 程式碼:
scene/resources/sky.cpp - Sky 資源(非天空算繪本身)
scene/resources/sky_material.cpp - SkyMaterial 資源(用於 Sky 資源)
天空算繪 GLSL 著色器:
體積霧
備註
僅於 Forward+ 算繪器中提供,Mobile 與 Compatibility 算繪器不支援。
也參考
Godot 採用視錐體對齊體素(froxel)方法進行體積霧算繪,這與傳統後處理濾鏡不同,更具通用性,能適用於各種光源。體積霧亦可用著色器自訂行為,例如製作動畫效果或用 3D 紋理表示密度。
FogMaterial 資源會自動為 FogVolume 節點產生內建著色器,與 BaseMaterial3D 處理 3D 場景材質的方式相同。
詳細技術說明可參見「Godot 4.0 新增 Fog Volumes <https://godotengine.org/article/fog-volumes-arrive-in-godot-4>」一文。
體積霧 C++ 程式碼:
scene/3d/fog_volume.cpp - FogVolume 節點
scene/resources/fog_material.cpp - FogMaterial 資源(FogVolume 專用)
體積霧 GLSL 著色器:
遮蔽剔除
即使現代 GPU 能處理大量三角形,複雜場景中的繪製呼叫數(Draw Call)仍然可能成為瓶頸(即便使用 Vulkan、Direct3D 12 或 Metal 亦然)。
Godot 4 支援遮蔽剔除,可降低過度繪製(若未啟用深度預通道)並減少頂點運算負擔。這是利用 Embree 於 CPU 上光柵化低解析度緩衝區來實現,緩衝區解析度取決於系統 CPU 執行緒數(會並行運作)。此緩衝區涵蓋編輯器內烘焙或執行時產生的遮蔽物形狀。
複雜遮蔽物會大幅增加 CPU 負擔,故於編輯器產生遮蔽物時可自動簡化其形狀。
Godot 的遮蔽剔除尚未支援動態遮蔽物,但 OccluderInstance3D 節點仍可切換可見性或移動。然而,這種方式若遇到複雜遮蔽物會極慢,因此建議僅對簡單形狀(如四邊形、立方體)於執行時更新遮蔽物。
這種以 CPU 為基礎的剔除方式,相較於門戶(Portals)房間法或 GPU 剔除方案有數項優勢:
無需人工設置(但可自訂調整以達最佳效能)。
無畫面延遲(Frame Delay)問題,這對於過場動畫、鏡頭切換或快速穿越牆壁的情境尤其有利。
各種算繪驅動與方法間行為一致,不會因驅動或 GPU 硬體不同而出現不可預期行為。
遮蔽剔除是透過註冊遮蔽物網格完成,方法為放置 OccluderInstance3D 節點*(其本身連結 Occluder3D *資源)。RenderingServer 會於 RendererSceneOcclusionCull 中呼叫 Embree 執行遮蔽剔除。
遮蔽剔除 C++ 程式碼:
可見範圍(LOD)
Godot 支援手動建立的階層式細節層級(HLOD),可於屬性面板為每個 LOD 指定啟用距離。
在 RenderingSceneCull 類別中,_scene_cull() 與 _render_scene() 函式負責決定 LOD。每個 Viewport 可對同一網格採用不同 LOD(以正確支援分割畫面算繪)。
可見範圍 C++ 程式碼:
自動網格 LOD
ImporterMesh 類別用於編輯器內 3D 網格匯入流程。其 generate_lods() 函式會呼叫 meshoptimizer 函式庫自動產生多層 LOD。
LOD 網格產生時,也會同步產生陰影網格。這些陰影網格會將頂點焊接(無論平滑或材質),以降低陰影算繪所需的頂點數,提升陰影效能。
RenderingSceneCull 類別的 _render_scene() 函式會決定算繪時使用哪個網格 LOD。每個 Viewport 可對同一網格採用不同 LOD(以正確支援分割畫面算繪)。
網格 LOD 會根據畫面覆蓋率自動選擇,會考慮解析度與攝影機視角變化,無需使用者手動調整。閾值倍數可於專案設定調整。
為提升效能,陰影算繪與反射探查算繪可自訂專用的網格 LOD 閾值(可與主場景不同)。
匯入時網格 LOD 產生 C++ 程式碼:
網格 LOD 判定 C++ 程式碼: