CPU 最佳化
效能量測
想要加速程式,我們必須先找出「瓶頸」在哪裡。瓶頸是指限制整體進度的最慢區段。專注於瓶頸可以讓我們集中精力優化最能帶來顯著效能提升的部分,而不是花大量時間在只會帶來微小提升的功能上。
對於 CPU 而言,找出瓶頸最簡單的方法就是使用效能分析器(Profiler)。
CPU 剖析器
剖析器會與你的程式同時執行,並量測每個函式所花費的時間比例。
Godot 編輯器內建了方便的剖析器。它不會在每次啟動專案時自動執行,必須手動啟動與停止。這是因為,和多數剖析器一樣,記錄這些時序資料會顯著拖慢你的專案速度。
剖析結束後,你可以回顧單一影格的結果。
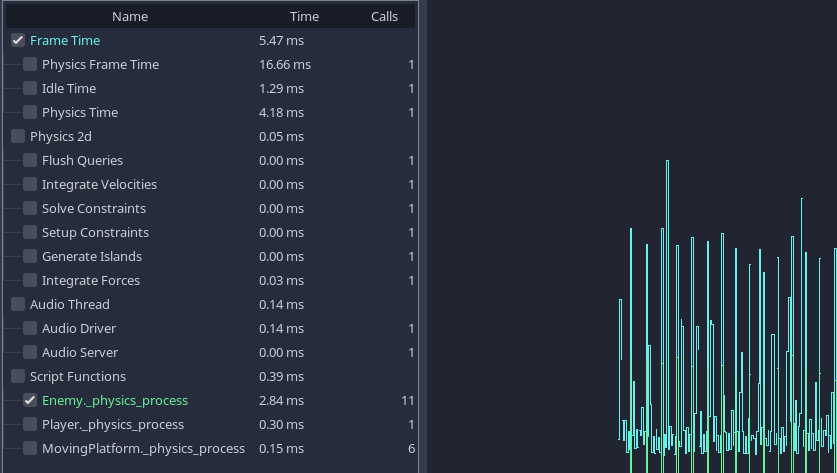
其中一個範例專案的剖析結果。
備註
我們可以看到內建流程(像是物理和音訊)的耗時,也能在下方看到自訂腳本函式的耗時。
等候各種內建伺服器的時間可能不會被剖析器計算在內。這是已知的 bug。
當專案執行緩慢時,通常會看到某個明顯的函式或流程用時遠高於其他部分。這就是你的主要瓶頸,通常只要優化這個區段,就能明顯提升效能。
更多關於 Godot 內建剖析器的資訊,請參考 除錯器面板。
外部剖析器
雖然 Godot 編輯器內建的剖析器非常方便實用,但有時候你可能需要更強大的功能,例如針對 Godot 引擎本身的原始碼進行剖析。
你可以 使用多款第三方 C++ 剖析器 來達成這個目的。
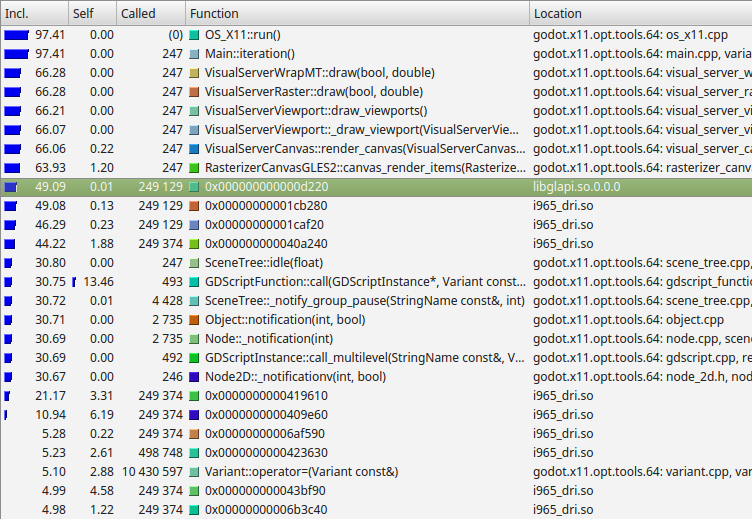
這是 Valgrind 套件中 Callgrind 的剖析結果範例。
從左至右,Callgrind 依序列出函式本身及其子函式執行時間比例(Inclusive),僅函式本身執行時間比例(Self),呼叫次數,函式名稱,以及所在檔案或模組。
在這個例子中,我們可以看到幾乎所有時間都耗在 Main::iteration() 這個函式下。這是 Godot 原始碼裡會反覆呼叫的主迴圈函式,負責觸發影格繪製、物理模擬、節點與腳本的更新。本例因為是 2D 基準測試,有 66% 的時間花在畫布算繪相關函式。再往下看,近 50% 的時間花在 Godot 以外的 libglapi 與 i965_dri (顯示卡驅動)。這顯示出大量 CPU 時間都消耗在圖形驅動上。
這其實是很好的案例,因為理論上,圖形驅動理應占用極少比例的 CPU 時間。這表示圖形 API 存在過多資料傳遞與工作負擔。這次剖析實驗促成 2D 批次處理技術的誕生,大幅減少該區段瓶頸,進而提升 2D 算繪效能。
手動量測函式效能
另一個實用技巧,尤其是在你用剖析器找出瓶頸後,就是手動量測特定函式或區段的執行時間。做法會依語言而異,在 GDScript 中你可以這樣做:
var time_start = Time.get_ticks_usec()
# Your function you want to time
update_enemies()
var time_end = Time.get_ticks_usec()
print("update_enemies() took %d microseconds" % time_end - time_start)
var timeStart = Time.GetTicksUsec();
// Your function you want to time.
UpdateEnemies();
var timeEnd = Time.GetTicksUsec();
GD.Print($"UpdateEnemies() took {timeEnd - timeStart} microseconds");
手動量測函式時,建議將函式重複執行多次(例如 1,000 次以上),而非只測一次(除非該函式極慢)。這是因為計時器精度有限,而且 CPU 行程排程具有隨機性。因此,取多次平均值會比單次結果準確許多。
試圖優化函式時,務必反覆進行剖析或量測,才能獲得關鍵回饋,了解優化是否真的奏效。
快取(Cache)
CPU 快取(Cache)是你在比較兩個函式版本效能時務必留意的重點。結果往往取決於資料是否已經在快取中。雖然系統記憶體(RAM)比 CPU 快取大很多(以 GB 計而快取僅數 MB),但 CPU 不會直接從 RAM 讀取,因為 RAM 存取速度很慢。CPU 會先從較小、但更快的快取記憶體存取資料。如果資料已在快取,載入速度極快;但若載入位址不在快取,就必須從主記憶體慢慢載入,造成 CPU 長時間閒置,這種狀況稱為「快取未命中(cache miss)」。
這代表第一次執行某個函式時,可能會很慢,因為資料還沒進入 CPU 快取。之後再執行可能會快很多,因為資料已經在快取裡了。因此計時時務必取多次平均值,並注意快取帶來的影響。
理解快取機制對 CPU 效能最佳化也非常關鍵。如果你的演算法(或常式)會隨機從主記憶體各處讀取零碎資料,很容易發生大量快取未命中,讓 CPU 大多時間都在等資料而無法運作。若能讓資料存取更具在地性,或最好使用線性(連續)存取(像連續陣列),快取效果就能發揮到最大,CPU 運作效率也會顯著提升。
Godot 通常會自動幫你處理這些底層細節。例如伺服器 API 已針對算繪和物理等資料做快取優化。不過,在撰寫 GDExtension 等原生擴充程式時,你還是要特別注意快取機制。
程式語言
Godot 支援多種語言,各有優缺點。有些語言為了易用性而犧牲速度,有些則速度快但較難使用。
無論你選擇哪種腳本語言,Godot 內建引擎函式的速度都一樣。但如果你的專案有大量自訂運算,建議考慮用更快的語言來處理這些運算。
GDScript
GDScript 設計重視易用與快速迭代,非常適合製作各種類型的遊戲。不過在此語言中,易用性比效能更被看重。若需要進行大量計算,建議將專案部分邏輯移至其他語言。
C#
C# 在 Godot 中相當受歡迎且有一級支援。它在速度與易用性之間取得了不錯的折衷。不過要注意在遊戲過程中可能發生的垃圾回收停頓與洩漏。常見的因應方式是使用 物件池(Object Pooling),但這超出本指南範圍。
其他語言
社群也提供多種其他語言的支援,例如 Rust。
C++
Godot 是用 C++ 編寫的,使用 C++ 通常能帶來最快效能。但實務上,C++ 專案在跨平台部署時最為困難。C++ 擴充方式有 GDExtension 及 自訂模組。
執行緒
如果你的運算可平行處理,建議善用「執行緒」。現代 CPU 多為多核心,各核心可同時處理不同工作。將運算分散到多執行緒,能更有效發揮 CPU 效率。
執行緒的缺點是必須小心避免競爭狀態(Race Condition)。每個 CPU 核心獨立運作,可能同時存取同一記憶體位置。一個執行緒可能正在讀取變數,另一個則在寫入,這就是 競爭狀態。在使用多執行緒之前,請務必瞭解相關風險與預防方式,因為多執行緒會讓除錯難度大幅提升。
更多關於執行緒的詳細資訊,請參閱 使用多執行緒。
SceneTree
節點(Node)雖然非常強大且彈性高,但每個節點都會帶來效能負擔。像 _process()、_physics_process() 等內建函式會遍歷整個樹狀結構。當你的專案包含大量節點時(數千至數萬,依平台而異),這些管理開銷會大幅影響效能。建議開發時務必針對所有目標平台進行效能檢測與剖析。
Godot 算繪器會逐一處理每個節點,因此減少節點數、將更多內容集中在單一節點,效能表現會更佳。
SceneTree 有個特性:你可以將節點從場景樹移除(而非只暫停或隱藏),這樣效能會更好。你不一定要刪除該節點——例如可以保留節點參考,用 Node.remove_child(node) 拆下,之後再用 Node.add_child(node) 加回來。這對於切換遊戲區域等場景非常實用。
你也可以選擇完全不用 SceneTree,直接用 Server API 處理。詳情請參見 使用伺服器進行最佳化。
物理
在某些情境下,物理運算會成為主要瓶頸。尤其是世界龐大或有大量物理物件時更是如此。
以下是提升物理效能的幾個技巧:
碰撞形狀建議用簡化版幾何圖形。這通常對玩家來說感覺不到差異,但能大幅提升效能。
當物件離開畫面或當前區域時,可以暫時將它們從物理世界移除,或重複利用物理物件(例如每個區域只需 8 隻怪物時就重用這 8 隻)。
物理運算的另一個重點是「物理更新頻率」(tick rate)。某些遊戲可以將更新頻率從每秒 60 次降到 30 次甚至 20 次,這能大幅減輕 CPU 負擔。
調整物理更新頻率的缺點是,當更新頻率與算繪影格速率不一致時,容易出現卡頓或抖動,而且降低更新頻率會增加輸入延遲。若遊戲需要即時玩家操作,建議維持預設 60Hz 物理更新頻率。
解決抖動的方法是使用 固定時間步長插值,也就是在多個影格之間平滑顯示的位置與旋轉來配合物理。Godot 內建物理插值,詳見 此處。就效能而言,插值相較於執行一次物理計算成本非常低,速度快上數個數量級,因此能在降低抖動的同時帶來顯著的效能提升。