Attention: Here be dragons
This is the latest
(unstable) version of this documentation, which may document features
not available in or compatible with released stable versions of Godot.
Checking the stable version of the documentation...
Оптимизация CPU
Замер производительности
Нам необходимо знать, где находятся "узкие места", чтобы знать, как ускорить нашу программу. Узкие места — это самые медленные части программы, ограничивающие скорость её выполнения. Сосредоточение внимания на "узких местах" позволяет нам сосредоточить усилия на оптимизации областей, которые обеспечат максимальный прирост скорости, вместо того, чтобы тратить много времени на оптимизацию функций, приводящую к небольшому повышению производительности.
Для CPU самый простой способ выявить узкие места — использовать профайлер (profiler).
Профайлеры CPU
Профилировщики работают вместе с вашей программой и выполняют измерения времени, чтобы определить, какая доля времени тратится на каждую функцию.
Godot IDE имеет встроенный профилировщик (built-in profiler). Он не запускается при каждом запуске проекта: его необходимо запускать и останавливать вручную. Это связано с тем, что, как и в случае с большинством профилировщиков, запись этих измерений времени может значительно замедлить проект.
После профилирования вы можете просмотреть результаты для кадра.
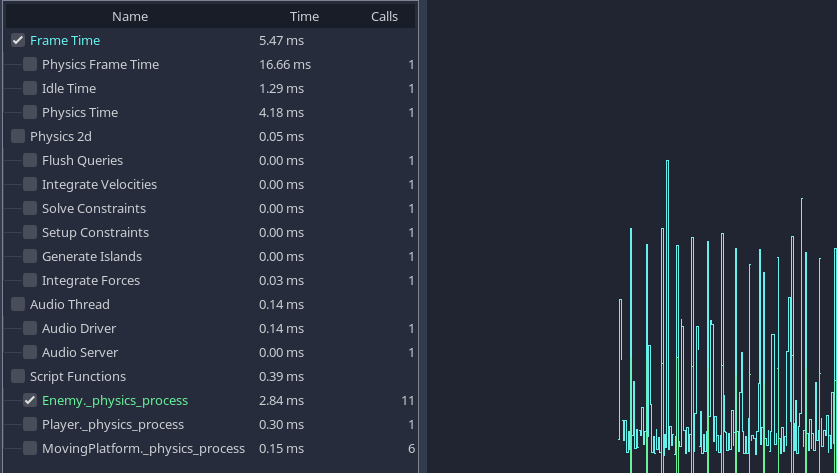
Результаты профиля одного из демонстрационных проектов.
Примечание
Мы можем увидеть стоимость встроенных процессов, таких как физика и звук, а также стоимость наших собственных функций скриптов внизу.
Время ожидания различных встроенных серверов может не учитываться в профилировщиках. Это известная ошибка.
Когда проект выполняется медленно, вы часто замечаете, что какая-то очевидная функция или процесс занимает гораздо больше времени, чем другие. Это ваше основное узкое место, и обычно можно повысить скорость, оптимизировав эту область.
Дополнительную информацию об использовании встроенного профилировщика Godot см. в разделе Панель Отладчика.
Внешние профилировщики (profilers)
Хотя профилировщик Godot IDE очень удобен и полезен, иногда вам требуется больше мощности и возможность профилировать сам исходный код движка Godot.
Для этого можно use a number of third-party C++ profilers (использовать ряд сторонних профилировщиков C++).
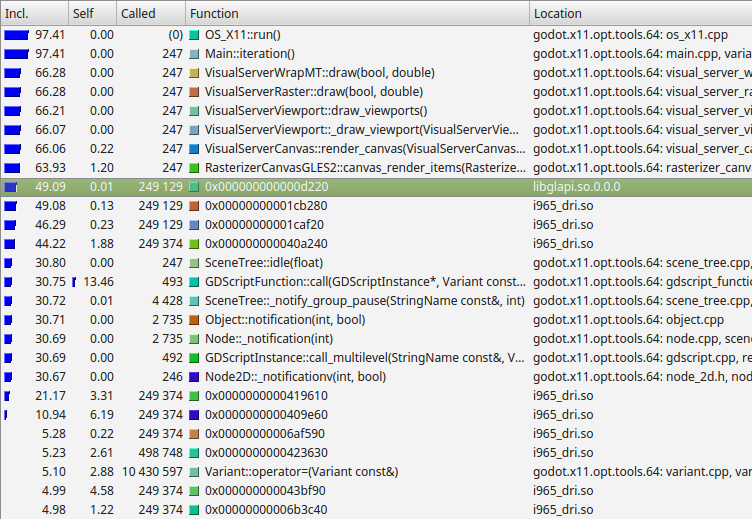
Примеры результатов Callgrind, который является частью Valgrind.
Слева направо Callgrind выводит процент времени, проведенного внутри функции и ее дочерних функций (включительно), процент времени, проведенного внутри самой функции, без учета дочерних функций (Self), количество вызовов функции, имя функции и файл или модуль.
В этом примере мы видим, что почти всё время тратится на функцию Main::iteration(). Это главная функция в исходном коде Godot, которая вызывается многократно. Она отвечает за отрисовку кадров, моделирование физических тиков, а также обновление узлов и скриптов. Значительная часть времени тратится на функции рендеринга холста (66%), поскольку в этом примере используется 2D-бенчмарк. Ниже мы видим, что почти 50% времени тратится вне кода Godot в libglapi и i965_dri (графическом драйвере). Это говорит о том, что значительная доля процессорного времени тратится на графический драйвер.
На самом деле, это отличный пример, поскольку в идеальном мире лишь очень малая часть времени тратилась бы на графический драйвер. Это указывает на проблему, связанную со слишком большим объемом обмена данными и работы в графическом API. Именно такое профилирование привело к разработке 2D-батчинга, который значительно ускоряет 2D-рендеринг, устраняя узкие места в этой области.
Функции ручного хронометража
Ещё один удобный метод, особенно после того, как вы определили узкое место с помощью профилировщика, — это вручную замерить время выполнения тестируемой функции или области. Конкретные действия различаются в зависимости от языка, но в GDScript это можно сделать следующим образом:
var time_start = Time.get_ticks_usec()
# Your function you want to time
update_enemies()
var time_end = Time.get_ticks_usec()
print("update_enemies() took %d microseconds" % (time_end - time_start))
var timeStart = Time.GetTicksUsec();
// Your function you want to time.
UpdateEnemies();
var timeEnd = Time.GetTicksUsec();
GD.Print($"UpdateEnemies() took {timeEnd - timeStart} microseconds");
При ручном синхронизации (timing ) функций обычно рекомендуется запускать функцию многократно (1000 или более раз), а не один раз (если только функция не очень медленная). Это обусловлено тем, что таймеры часто имеют ограниченную точность. Более того, процессоры планируют процессы хаотично. Поэтому среднее значение по серии запусков точнее, чем единичное измерение.
При оптимизации функций обязательно регулярно профилируйте их или засекайте время выполнения. Это даст вам важную обратную связь относительно того, работает ли оптимизация (или нет).
Кэши
Кэш-память процессора - это то, о чем следует помнить, особенно при сравнении временных результатов двух разных версий функции. Результаты могут сильно зависеть от того, находятся ли данные в кэше процессора или нет. Процессоры не загружают данные непосредственно из системной оперативной памяти, даже если она огромна по сравнению с кэшем процессора (несколько гигабайт вместо нескольких мегабайт). Это происходит потому, что доступ к системной оперативной памяти очень медленный. Вместо этого процессоры загружают данные из меньшего, более быстрого банка памяти, называемого кэш-памятью. Загрузка данных из кэша происходит очень быстро, но каждый раз, когда вы пытаетесь загрузить адрес памяти, который не хранится в кэше, кэш должен совершить путешествие в основную память и медленно загрузить данные. Эта задержка может привести к тому, что процессор будет долгое время простаивать, и называется "пропуском кэша".
Это означает, что при первом запуске функция может выполняться медленно, поскольку данные отсутствуют в кэше процессора. При втором и последующих запусках она может выполняться значительно быстрее, поскольку данные находятся в кэше. В связи с этим при измерении времени всегда используйте средние значения и учитывайте влияние кэша.
Понимание кэширования также имеет решающее значение для оптимизации процессора. Если у вас есть алгоритм (рутина), который загружает небольшие биты данных из произвольно распределенных областей основной памяти, это может привести к большому количеству пропусков кэша, и большую часть времени процессор будет ждать данных, вместо того чтобы выполнять какую-либо работу. Вместо этого, если вы можете сделать доступ к данным локализованным или, еще лучше, обращаться к памяти линейно (как к непрерывному списку), тогда кэш будет работать оптимально, а процессор сможет работать максимально быстро.
Godot обычно берёт на себя заботу о таких низкоуровневых деталях. Например, API сервера обеспечивают оптимизацию данных для кэширования уже для таких задач, как рендеринг и физика. Тем не менее, при написании GDExtensions следует быть особенно внимательным к кэшированию.
Языки
Godot поддерживает ряд различных языков, и стоит помнить о компромиссах. Некоторые языки разработаны для удобства использования в ущерб скорости, а другие быстрее, но с ними сложнее работать.
Встроенные функции движка работают с одинаковой скоростью независимо от выбранного языка программирования. Если ваш проект выполняет множество вычислений в собственном коде, рассмотрите возможность переноса этих вычислений на более быстрый язык.
GDScript
GDScript разработан для удобства использования и итераций и идеально подходит для создания самых разных игр. Однако в этом языке простота использования считается важнее производительности. Если вам нужно выполнять сложные вычисления, рассмотрите возможность переноса части вашего проекта на один из других языков.
C#
C# популярен и имеет первоклассную поддержку в Godot. Он предлагает хороший компромисс между скоростью и простотой использования. Однако будьте осторожны с возможными паузами в сборке мусора и утечками, которые могут возникнуть во время игры. Распространённый подход к решению проблем со сборкой мусора — использование object pooling, что выходит за рамки данного руководства.
Другие языки
Третьи стороны обеспечивают поддержку нескольких других языков, включая Rust.
C++
Godot написан на C++. Использование C++ обычно обеспечивает самый быстрый код. Однако на практике его сложнее всего развернуть на компьютерах конечных пользователей на разных платформах. Варианты использования C++ включают GDExtensions и custom modules.
Потоки
Рассмотрите возможность использования потоков при выполнении большого количества вычислений, которые могут выполняться параллельно. Современные процессоры имеют несколько ядер, каждое из которых способно выполнять ограниченный объём работы. Распределяя нагрузку между несколькими потоками, можно добиться максимальной эффективности процессора.
Недостаток потоков заключается в необходимости соблюдать крайнюю осторожность. Поскольку каждое ядро процессора работает независимо, они могут одновременно пытаться получить доступ к одной и той же памяти. Один поток может читать переменную, пока другой записывает её: это называется состоянием гонки. Прежде чем использовать потоки, убедитесь, что вы понимаете связанные с ними опасности и знаете, как предотвратить эти состояния гонки. Потоки могут значительно усложнить отладку.
Более подробную информацию о потоках см. Использование многопоточности.
Дерево сцены
Хотя Узлы (Nodes) — невероятно мощная и универсальная концепция, помните, что каждый узел имеет свою стоимость. Встроенные функции, такие как _process() и _physics_process(), распространяются по всему дереву. Эта функция может снизить производительность при очень большом количестве узлов (точное количество зависит от целевой платформы и может варьироваться от тысяч до десятков тысяч, поэтому обязательно оцените производительность на всех целевых платформах во время разработки).
Каждый узел обрабатывается отдельно в рендерере Godot. Поэтому меньшее количество узлов и большее количество каждого из них может привести к лучшей производительности.
Одна из особенностей SceneTree заключается в том, что иногда можно добиться гораздо большей производительности, удаляя узлы из SceneTree, а не приостанавливая или скрывая их. Удалять отсоединённый узел не обязательно. Например, можно сохранить ссылку на узел, отсоединить его от дерева сцены с помощью Node.remove_child(node), а затем снова присоединить его позже с помощью Node.add_child(node). Это может быть очень полезно, например, для добавления и удаления областей в игре.
Вы можете полностью отказаться от SceneTree, используя серверные API. Подробнее см. Оптимизация с помощью серверов.
Физика
В некоторых ситуациях физика может стать узким местом. Это особенно актуально в сложных мирах и с большим количеством физических объектов.
Вот несколько приемов для ускорения физики:
Попробуйте использовать упрощённые версии визуализированной геометрии для форм столкновений. Зачастую это незаметно для конечных пользователей, но может значительно повысить производительность.
Попробуйте удалить объекты из физики, когда они находятся вне поля зрения/за пределами текущей области, или повторно использовать физические объекты (например, можно разрешить 8 монстров на область и повторно использовать их).
Другим важным аспектом физики является частота тиков. В некоторых играх её можно значительно снизить, например, вместо обновления физики 60 раз в секунду, а можно обновлять её всего 30 или даже 20 раз в секунду. Это может значительно снизить нагрузку на процессор.
Недостатком изменения частоты физических тиков является возможность возникновения рывков или дрожания, когда частота обновления физики не соответствует количеству кадров в секунду. Кроме того, уменьшение частоты физических тиков увеличит задержку ввода. В большинстве игр с движением игрока в реальном времени рекомендуется придерживаться частоты физических тиков по умолчанию (60 Гц).
Решением проблемы дрожания является использование интерполяции с фиксированным временным шагом, которая включает сглаживание визуализированных положений и поворотов в нескольких кадрах для соответствия физике. Godot имеет встроенную физическую интерполяцию, о которой вы можете прочитать сдесь here. С точки зрения производительности интерполяция — очень дешевая операция по сравнению с выполнением физического тика. Он на порядок быстрее, так что это может дать существенный выигрыш в производительности, а также снизить дрожание (jitter).